 JDK源码中有趣的位运算
JDK源码中有趣的位运算
# JDK源码中有趣的位运算
本文全篇分析基于JDK1.8源码
# 1、ReentrantReadWriteLock中的位运算
# 1.1、前提分析
在ReentrantReadWriteLock源码上面有这样一段注释:
This lock supports a maximum of 65535 recursive write locks and 65535 read locks. Attempts to exceed these limits result in Error throws from locking methods.
为什么最大只支持65535个递归写锁和读锁呢?65535 = 2^{16} - 1 源码之下无秘密
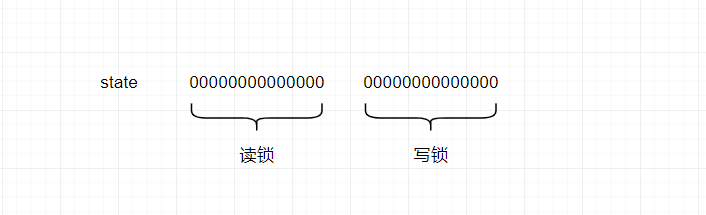
首先,我们需要知道ReentrantReadWriteLock的加锁原理,标识当前资源是否已经加锁,使用的是AQS内部的int类型的变量state来标识。
对于可重入锁ReentrantLock来说,标识加锁很简单,判断 state=0 或者 state>0就可以了,只要state>0,那就代表当前资源处于锁定状态,但是对于ReentrantReadWriteLock来说,加锁有两种状态,读锁和写锁,读锁可以共享,写锁代表互斥,那一个state变量怎么来标识两种锁的状态呢?
先复习一下基础知识:int类型占用4个字节(byte),一个字节占用8位(比特bite),也就是说一个int类型的变量在操纵系统看来一共占用32位,也就是32个0或者1的组合,举例如下:
int i = 1; 那 i 在操作系统看来就是 0000000000000000000000000000001
int i = 2; 那 i 在操作系统看来就是 0000000000000000000000000000010
为了解决一个state变量来标识两个锁的状态,JDK开发人员,把state的32位分为了高16位和低16位,其中如果加了读锁,那就是在高16位上面进行位运算;如果是加了写锁,那就在state的低16位上面进行位运算
# 1.2、源码分析
具体在源码中看一下加锁和解锁的各种写法
ReentrantReadWriteLock rw = new ReentrantReadWriteLock();
ReentrantReadWriteLock.ReadLock r = rw.readLock();
ReentrantReadWriteLock.WriteLock w = rw.writeLock();
//读锁 加锁
r.lock();
//读锁 解锁
r.unlock();
//写锁 加锁
w.lock();
//写锁 解锁
w.unlock();
2
3
4
5
6
7
8
9
10
11
# 1.2.1、读锁 加锁
读锁加锁会直接调用sync.acquireShared(1)方法,其中Sync是ReentrantReadWriteLock中基于AQS的实现的一个同步器
其中Sync内部有比较重要的四个属性,两个方法,如下代码所示
// 读取与写入计数提取常量和函数
// 锁状态在逻辑上分为两个无符号短整型:下部表示独占(写入器)锁定保持计数,上部表示共享(读取器)保持计数
static final int SHARED_SHIFT = 16;
// 1 << 16 代表1左位移16,也就是 00000000 00000001 00000000 00000000 也就是所谓的高16位的开始
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
// 1 << 16 -1 代表1左位移16再减去1,也就是 00000000 00000000 111111111 11111111 也就是所谓的低16位的开始
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
// 1 << 16 -1 代表1左位移16再减去1,也就是 00000000 00000000 111111111 11111111 也就是所谓的低16位的开始
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
/**
* 返回以计数表示的共享保留项数 >>> 代表无符号右移16位
* c 进行无符号右移16位
* int总共32位,所以结果就是高16位全部替换为0,原先的低16位全部抛弃,原先的高16位变成低16位,而原先的高 * 16位代表的读锁,所以这个操作得到的结果就是当前资源被设置读锁的个数
*/
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
/**
* 返回以计数表示的独占保留数 & 代表与运算
* c 和 00000000 00000000 111111111 11111111 进行 & 运算 全1为1,别的都是0
* 也就是说 不论c的值是多少,和EXCLUSIVE_MASK进行&运算,得到的结果高16位一直都是0,低16位和c保持一致
* 换个说法,只要是当前资源加的是读锁,那么这个方法会一直返回0,也就对应了这个方法的名字返回写锁的数量
*/
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
回到正题,加锁的时候会调用sync.acquireShared(1)方法,acquireShared方法内部会先尝试获取锁
1、会获取当前的state值 赋值为 c = 0
2、判断有没有写锁 exclusiveCount(c) != 0
3、如果没有写锁,则对c进行无符号右移16位,赋值给r 得到 加读锁的个数为0
4、然后判断r是否小于MAX_COUNT,这一步判断当前加锁的个数是不是小于最大加锁数量
5、通过CAS更改c的值,c = c+ SHARED_UNIT, 也就是高16位+1
6、第一次加锁成功,结果就是state值为 00000000 00000001 00000000 00000000
//只显示和位运算相关的代码
/**
* exclusiveCount(c) != 0 这个条件只有在 c = 0的情况下,exclusiveCount(c) 才会等于0
* 第一次加锁,c=0,所以当前判断会跳过
*/
if (exclusiveCount(c) != 0 && getExclusiveOwnerThread() != current) return -1;
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)){...}
2
3
4
5
6
7
8
9
10
11
12
13
如果是第二次加读锁,整个过程如下:
1、获取当前state值,赋值为c = 00000000 00000001 00000000 00000000
2、判断有没有写锁exclusiveCount(c) != 0
3、则对c进行无符号右移16位,赋值给r 得到 加读锁的个数为1
4、CAS更改c的值,c = c+ SHARED_UNIT, 也就是高16位+1
5、第二次加锁成功,结果就是state值为 00000000 00000010 00000000 00000000
# 1.2.2、读锁 解锁
//忽略线程代码解析....
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
2
3
4
5
6
7
1、获取当前state值 00000000 00000010 00000000 00000000
2、在state高16位进行-1的操作 得到nextc = 00000000 00000001 00000000 00000000
3、CAS赋值,然后判断此时nextc是否==0,如果只有一个读锁的情况,那此时就是0 ,如果是多个读锁,则不是,返回false
# 1.2.3、写锁 加锁
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
// (Note: if c != 0 and w == 0 then shared count != 0)
if (w == 0 || current != getExclusiveOwnerThread())
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
setState(c + acquires);
return true;
}
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current);
return true;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
1、获取当前state值 c = 0
2、获取当前写锁的个数 w = 0
3、如果c != 0,说明当前资源有被锁定,如果w==0,代表此时没有写锁,那肯定是有读锁,返回加锁失败
4、此时c = 0,执行13行,对c进行赋值+1,然后设置写锁线程为当前线程
如果是别的线程第二次加写锁:
1、获取当前state值 c = 1
2、获取当前写锁的个数 w 此时 w = 1
3、然后判断当前线程是不是已经加锁的线程,如果是则累加,如果不是则返回false
4、当前加锁线程进入队列等待
# 1.2.4、写锁 解锁
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int nextc = getState() - releases;
boolean free = exclusiveCount(nextc) == 0;
if (free)
setExclusiveOwnerThread(null);
setState(nextc);
return free;
2
3
4
5
6
7
8
1、获取state 减去releases 1, 得到的结果nextc,
2、判断当前剩余的锁数量是否是0
3、如果是0则把Thead变量赋值为null
4、state 赋值nextc
# 2、HashMap中的位运算
# 2.1、容量是2的n次方
HashMap代码保证了整个Map的容量都是2的n次方,比如构造函数传入的大小为5,那么真实的容量就是大于5的最小2的n次方,也就是2的3次方=8
HashMap m = new HashMap<String,String>(5);
m.size();// 8
具体看一下代码中的实现:
假如传入的n是10,也就是new HashMap<String,String>(10);代码中的操作如图所示:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
2
3
4
5
6
7
8
9
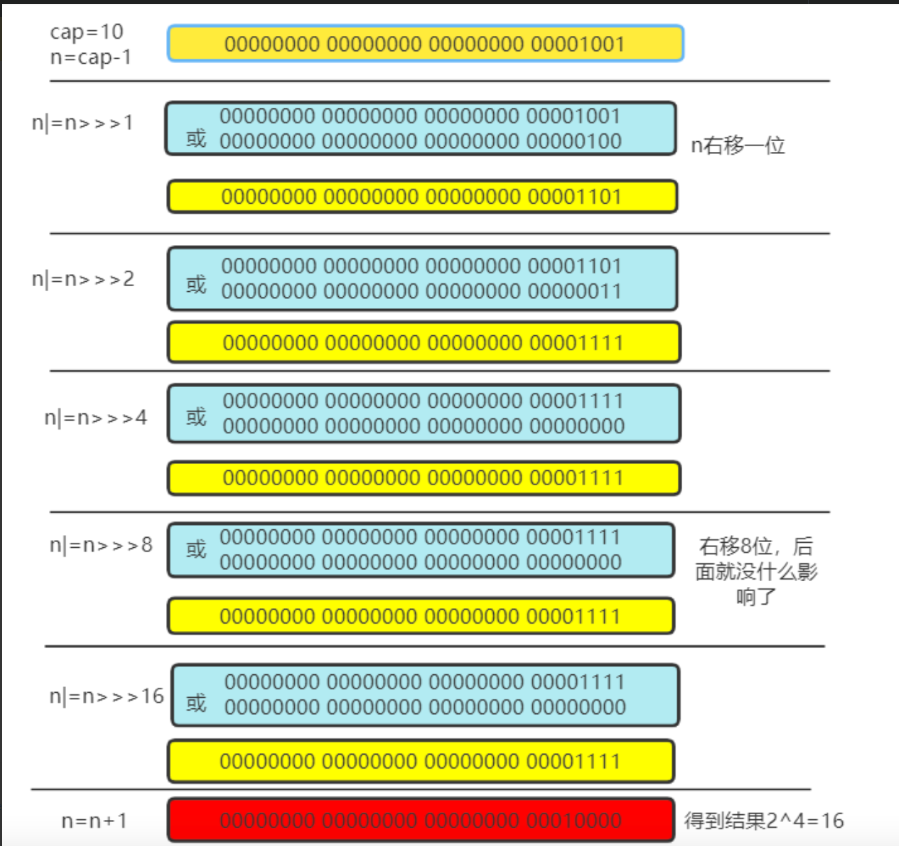
为什么要对cap做-1的操作? 这是为了防止cap已经是2的n次方了,如果cap已经是2的n次方,又没有进行-1操作,那么得到的将会是cap的2倍,比如传入的cap是16,满足2的n次方,但是不进行-1,最终得到的值将会是32
最大容量:容量最大也就是32bit的正数,因为最后 n |= n >>> 16,最多也就是32个1,但是已经是负数了,在执行tableSizeFor之前,会对initialCapacity进行判断,如果大于MAXIMUM_CAPACITY(2 ^ 30),则取MAXIMUM_CAPACITY,如果等于MAXIMUM_CAPACITY,则进行位运算,结果会是最大30个1,最后一步+1返回值是2^30
# 2.2、扩容的位运算
当HashMap中的元素个数超过capacity(数组长度默认16) * loadFactor(负载因子默认0.75时,就会进行数组扩容,loadFactor的默认值(DEFAULT_LOAD_FACTOR)是0.75,这是一个折中的取值
也就是说默认情况下 16*0.75 = 12,如果元素个数超过12,就会进行扩容,把数组大小扩大两倍就是16*2=32,然后重新计算元素在数组中的位置,这是一个非常消耗性能的操作,所以如果我们开发过程中已经预知map中的元素个数,需要在构造函数中加入预期的元素个数,这能有效的减少扩容的触发。
扩容:因为每次扩容都是翻倍,与原来计算的(n-1)&hash的结果相比,只是多了一个bit位,所以节点要么在原来的位置上,要么就被分配到原位置+旧位置的位置,例如 从16扩容到32的过程,具体变化如下所示


容量变为原来的2倍后,n-1的二进制数也由1111变为了11111,当容量为16时,(n-1)&hash的值都是0101,也就是十进制的5;当容量变化为32时,hash1的结果是0101,十进制的5,hash2的结果是10101,十进制的21(5+16)。所以扩容后的节点要么在原位置,要么在原位置+旧位置。因此,在扩充hashMap的时候,不需要重新计算hash,只需要看一下原来的hash值新增的bit是0还是1,如果是0代表索引没变,如果是1就变成了原索引+oldCap(原位置+旧容量),源码中通过e.hash & oldCap进行判断。
oldCap就是扩容之前的容量,在上面的例子中就是16,hash1的结果为0,表示在原位置,hash2的结果为1,表示在5+16 =21的位置
可以看一下16扩容到32点resize示意图
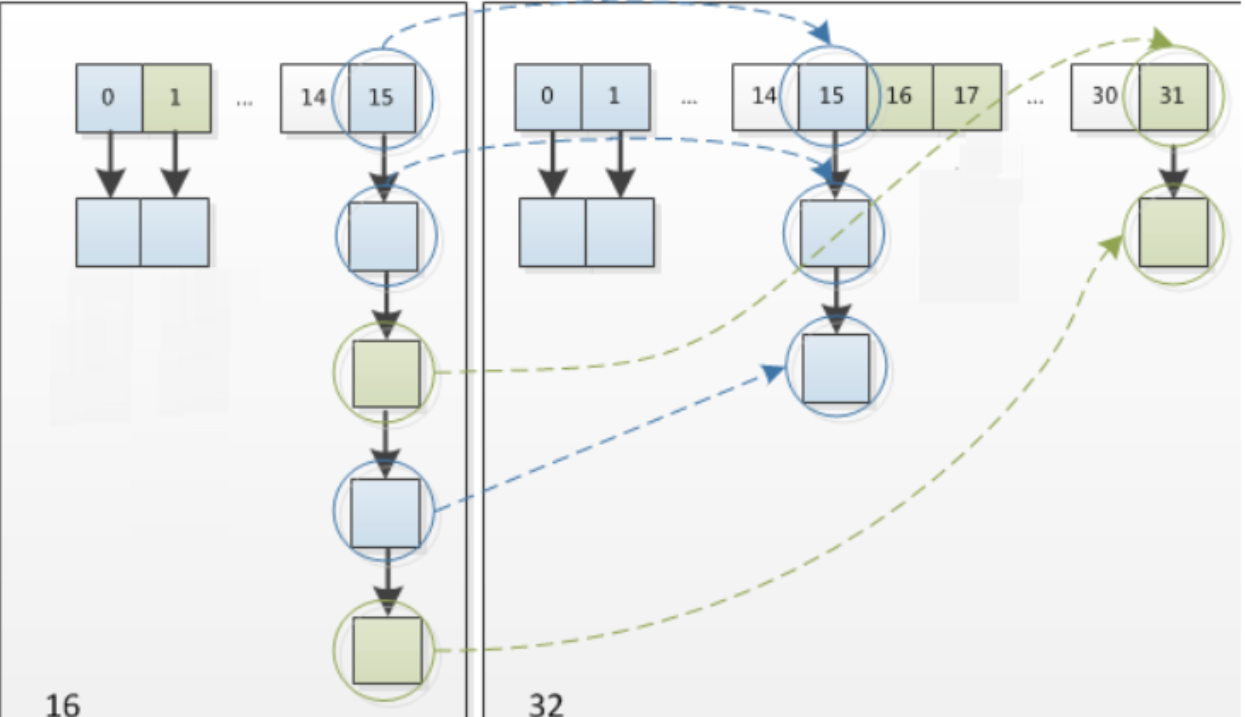
正是因为这种巧妙的方式,既省去了重新计算hash的时间,而且同时由于新增的bit是0还是1可以认为是随机的,在resize的过程中保证了每次rehash之后每个桶上的节点数肯定是小于等于原先桶上的节点数,保证了rehash之后不会出现更严重的哈希冲突,均匀的把之前的冲突分配到了不同的桶上
源码如下:
final Node<K,V>[] resize() {
//得到当前数组
Node<K,V>[] oldTab = table;
//如果当前数组等于null长度返回0,否则返回当前数组的长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//当前阈值点 默认是12(16*0.75)
int oldThr = threshold;
int newCap, newThr = 0;
//如果老的数组长度大于0
//开始计算扩容后的大小
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
//修改阈值为int的最大值
threshold = Integer.MAX_VALUE;
return oldTab;
}
/*
没超过最大值,就扩充为原来的2倍 1)(newCap = oldCap << 1) < MAXIMUM_CAPACITY
扩大到2倍之后容量要小于最大容量 2)oldCap >= DEFAULT_INITIAL_CAPACITY
原数组长度大于等于数组初始化长度16
*/
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY
&& oldCap >= DEFAULT_INITIAL_CAPACITY)
//阈值扩大一倍
newThr = oldThr << 1;
// double threshold
}
//老阈值点大于0 直接赋值
else if (oldThr > 0)
// 老阈值赋值给新的数组长度
newCap = oldThr;
else {
// 直接使用默认值
newCap = DEFAULT_INITIAL_CAPACITY;
//16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize最大上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY
&& ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
//新的阈值 默认原来是12 乘以2之后变为24
threshold = newThr;
//创建新的哈希表
@SuppressWarnings({ "rawtypes","unchecked"})
//newCap是新的数组长度32
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//判断旧数组是否等于空
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
//遍历旧的哈希表的每个桶,重新计算桶里元素的新位置
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
//原来的数据赋值为null 便于GC回收
oldTab[j] = null;
//判断数组是否有下一个引用
if (e.next == null)
//没有下一个引用,说明不是链表,当前桶上只有一个键值对,直接插入
newTab[e.hash & (newCap - 1)] = e;
//判断是否是红黑树
else if (e instanceof TreeNode)
//说明是红黑树来处理冲突的,则调用相关方法把树分开
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 采用链表处理冲突
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//通过上述讲解的原理来计算节点的新位置
do {
// 原索引
next = e.next;
//这里来判断如果等于true e这个节点在resize之后不需要移动位置
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
}
while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111