 Mybatis源码
Mybatis源码
本文全部内容来自于《通用源码阅读指导书-MyBatis源码详解》,属于读后做一个简单记录
# 一、整体调用流程
代码实现:
 代码流程解析
代码流程解析

# 1、项目使用的设计模式整理:
- 适配器模式
- logging包:JakartaCommonsLoggingImpl是一个典型的对象适配器,内部持有了Log对象,然后把所有方法委托给了该对象
- 模板模式
- Type包:BaseTypeHandler中的getResult方法完成了一系列 的异常处理工作,而与类型相关的getNullableResult操作则通过抽象方法交给具体的类型处理器,这就是典型的模板模式
- 单例模式
- IO包:VFS包含的VFSHolder就是一个单例
- 代理模式
- IO包:JBoss6VFS类中的ViryualFile是JBoss中的ViryualFile的静态代理类
- logging:jdbc子包使用代理模式,让mybatis能够打印jdbc的操作日志,方便进行调试
- binding包:数据库接入MapperProxy
- 建造者模式:
- builder包
- 工厂模式
- datasource包
- 装饰器模式
- cache包
- 责任链模式
- plugin包
# 二、源码结构展示
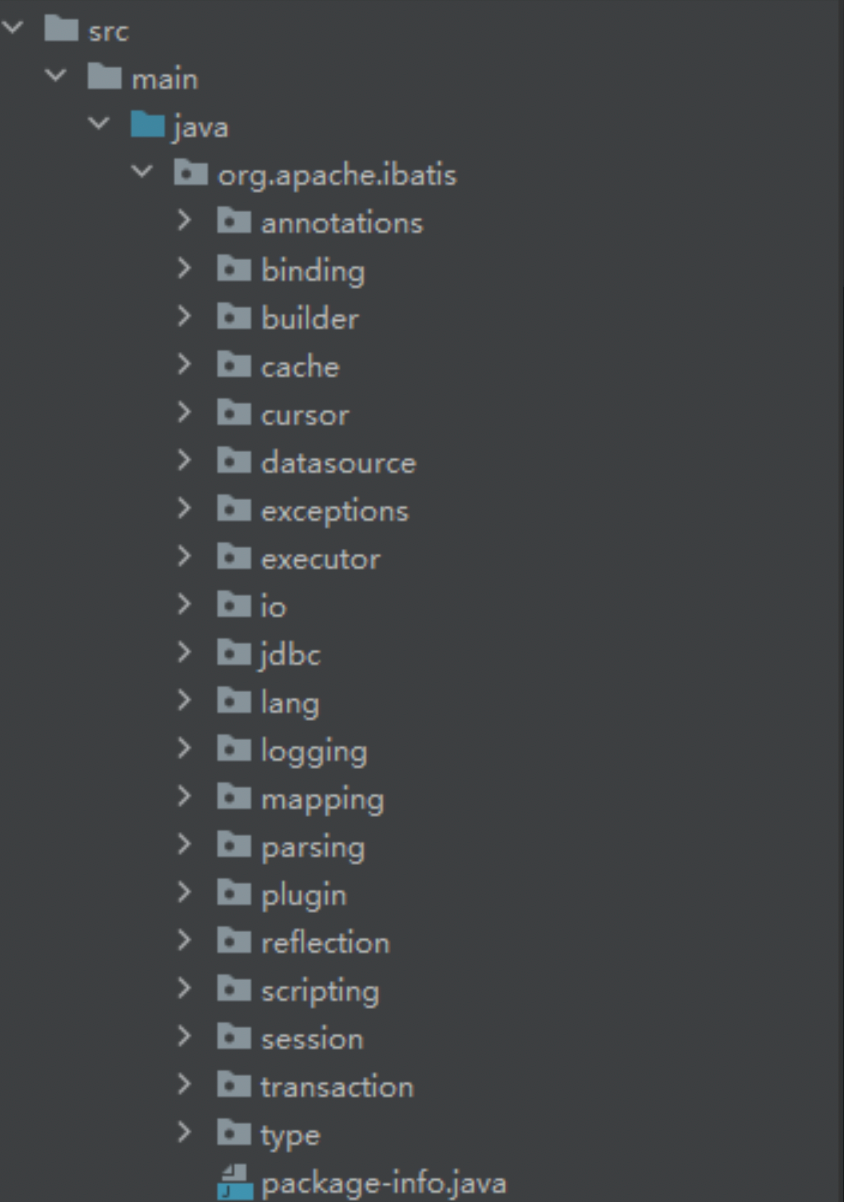 基础功能包:
基础功能包:
- exceptions
- reflection
- annotations
- lang
- type
- io
- logging
- parsing
配置解析包:
- binding
- builder
- mapping
- scripting
- datasource
核心操作包:
- jdbc
- cache
- transaction
- cursor
- executor
- session
- plugin
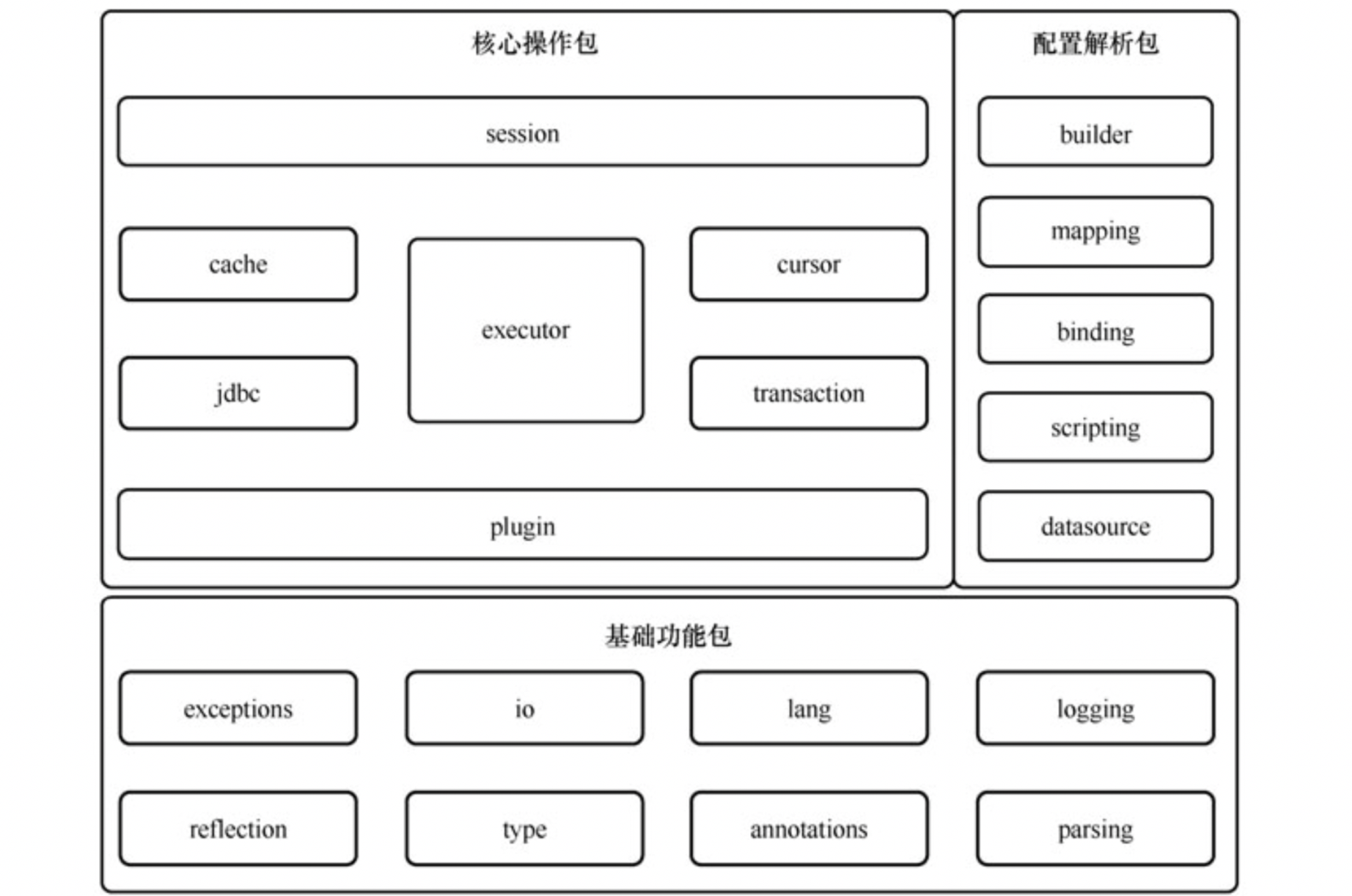
# 三、源码包解析
# 1、reflection包(反射包)
# 1.1、factory包(工厂包)
public interface ObjectFactory {
default void setProperties(Properties properties) {
}
<T> T create(Class<T> type);
<T> T create(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs);
<T> boolean isCollection(Class<T> type);
}
2
3
4
5
6
7
8
9
10
11
12
13
DefaultObjectFactory为当前接口的默认实现
public class DefaultObjectFactory implements ObjectFactory, Serializable {
private static final long serialVersionUID = -8855120656740914948L;
@Override
public <T> T create(Class<T> type) {
return create(type, null, null);
}
@SuppressWarnings("unchecked")
@Override
public <T> T create(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
Class<?> classToCreate = resolveInterface(type);
// we know types are assignable
// 创建类型实例
return (T) instantiateClass(classToCreate, constructorArgTypes, constructorArgs);
}
/**
* 创建类的实例
* @param type 要创建实例的类
* @param constructorArgTypes 构造方法入参类型
* @param constructorArgs 构造方法入参
* @param <T> 实例类型
* @return 创建的实例
*/
private <T> T instantiateClass(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
try {
// 构造方法
Constructor<T> constructor;
if (constructorArgTypes == null || constructorArgs == null) { // 参数类型列表为null或者参数列表为null
// 因此获取无参构造函数
constructor = type.getDeclaredConstructor();
try {
// 使用无参构造函数创建对象
return constructor.newInstance();
} catch (IllegalAccessException e) {
// 如果发生异常,则修改构造函数的访问属性后再次尝试
if (Reflector.canControlMemberAccessible()) {
constructor.setAccessible(true);
return constructor.newInstance();
} else {
throw e;
}
}
}
// 根据入参类型查找对应的构造器
constructor = type.getDeclaredConstructor(constructorArgTypes.toArray(new Class[constructorArgTypes.size()]));
try {
// 采用有参构造函数创建实例
return constructor.newInstance(constructorArgs.toArray(new Object[constructorArgs.size()]));
} catch (IllegalAccessException e) {
if (Reflector.canControlMemberAccessible()) {
// 如果发生异常,则修改构造函数的访问属性后再次尝试
constructor.setAccessible(true);
return constructor.newInstance(constructorArgs.toArray(new Object[constructorArgs.size()]));
} else {
throw e;
}
}
} catch (Exception e) {
// 收集所有的参数类型
String argTypes = Optional.ofNullable(constructorArgTypes).orElseGet(Collections::emptyList)
.stream().map(Class::getSimpleName).collect(Collectors.joining(","));
// 收集所有的参数
String argValues = Optional.ofNullable(constructorArgs).orElseGet(Collections::emptyList)
.stream().map(String::valueOf).collect(Collectors.joining(","));
throw new ReflectionException("Error instantiating " + type + " with invalid types (" + argTypes + ") or values (" + argValues + "). Cause: " + e, e);
}
}
// 判断要创建的目标对象的类型,即如果传入的是接口则给出它的一种实现
protected Class<?> resolveInterface(Class<?> type) {
Class<?> classToCreate;
if (type == List.class || type == Collection.class || type == Iterable.class) {
classToCreate = ArrayList.class;
} else if (type == Map.class) {
classToCreate = HashMap.class;
} else if (type == SortedSet.class) { // issue #510 Collections Support
classToCreate = TreeSet.class;
} else if (type == Set.class) {
classToCreate = HashSet.class;
} else {
classToCreate = type;
}
return classToCreate;
}
@Override
public <T> boolean isCollection(Class<T> type) {
return Collection.class.isAssignableFrom(type);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
# 1.2、invoker包(执行器)
该子包中的类能够基于反射实现对象方法的调用和对象属性的读写
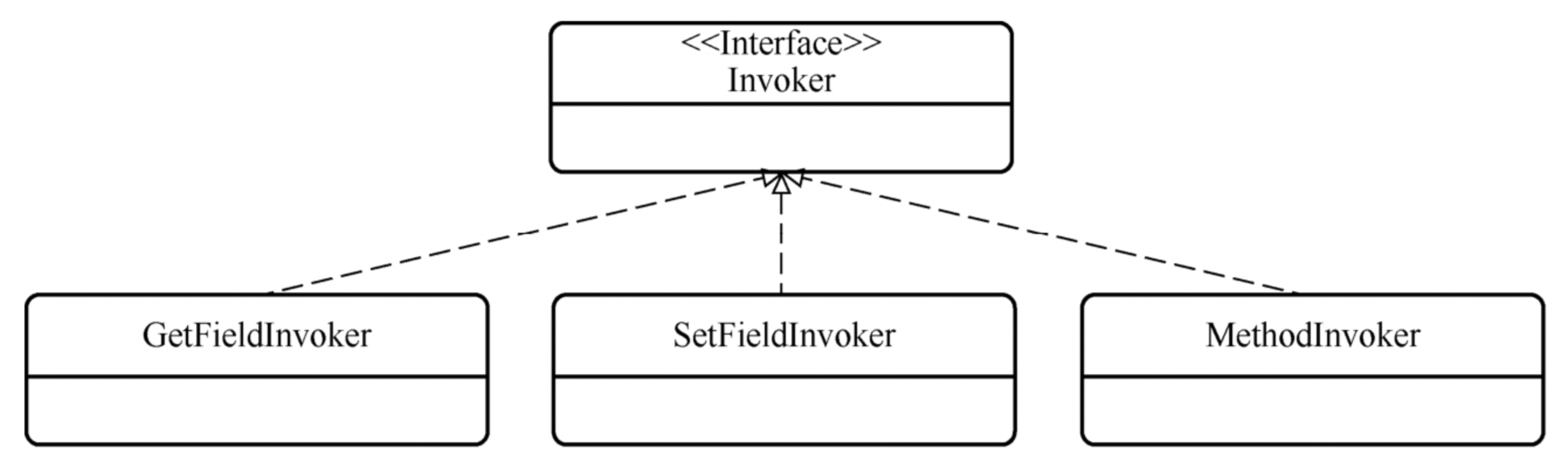
public interface Invoker {
// 方法执行调用器
Object invoke(Object target, Object[] args) throws IllegalAccessException, InvocationTargetException;
// 传入参数或者传出参数的类型(如有一个入参就是入参,否则是出参)
Class<?> getType();
}
2
3
4
5
6
三个默认实现: GetFieldInvoker:负责对象属性的读操作 SetFieldInvoker:负责对象属性的写操作 MethodInvoker:负责对象其它方法的操作
# 1.3、property包(属性)
该子包中的类用来完成与对象属性相关的操作
- PropertyCopier:属性拷贝器,可以方便的把一个对象的属性复制到另一个对象中
- copyBeanProperties方法的工作原理非常简单:通过反射获取类的所有属性,然后依次将这些属性值从源对象复制出来并赋给目标对象。但是要注意一点,该属性复制器无法完成继承得来的属性的复制,因为 getDeclaredFields方法返回的属性中不包含继承属性
- PropertyNamer:属性(包括属性方法)名称处理器
- PropertyTokenizer:是一个属性标记器。传入一个形如“student[sId].name”的字符串后,该标记器会将其拆分开,放入各个属性中
# 1.4、wrapper包(对象包装器)
使用装饰器模式对各种类型的对象进行进一步的封装,为其增加一些功能,使之更易于使用
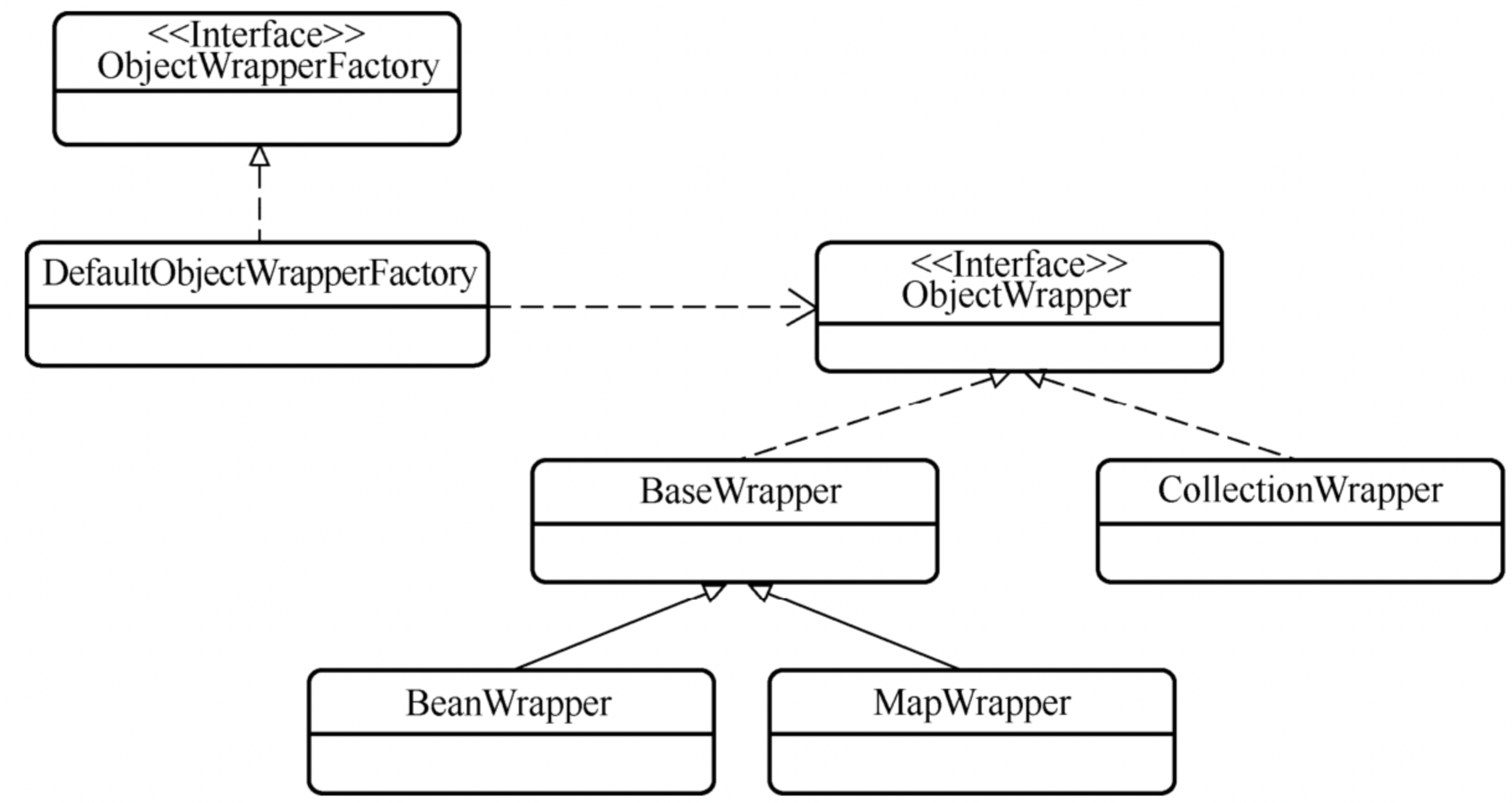
- ObjectWrapperFactory:是对象包装器工厂的接口,DefaultObjectWrapperFactory是默认实现,该默认节点没有实现任何功能,Mybatis也允许用户通过配置文件中的objcetWrapperFactory节点,来注入新的ObjectWrapperFactory
- ObjectWrapper:是所有对象包装器的总接口
- BeanWrapper:包含了一个Bean的对象信息、类型信息、并提供了更多的功能,一个bean通过BeanWrapper包装后就可以暴露大量的易用方法,可以简单的实现对其方法、属性的操作 get:获得被包装对象某个属性的值 set:设置被包装对象某个属性的值 findProperty:找到对应的属性值 getGetterNames:获取所有属性的get方法名称 getSetterNames:获得所有属性的set方法名称 getGetterType:获取指定属性的get方法的类型 getSetterType:获取指定属性的set方法的类型 hasGetter:判断某个属性是否有对应的get方法 hasSetter:判断某个属性是否有对应的set方法 instantiatePropertyValue:实例化某个属性的值
- MapWrapper:对于Map类型的包装
- CollectionWrapper:对于集合类型的封装
# 1.5、reflector(反射核心类)
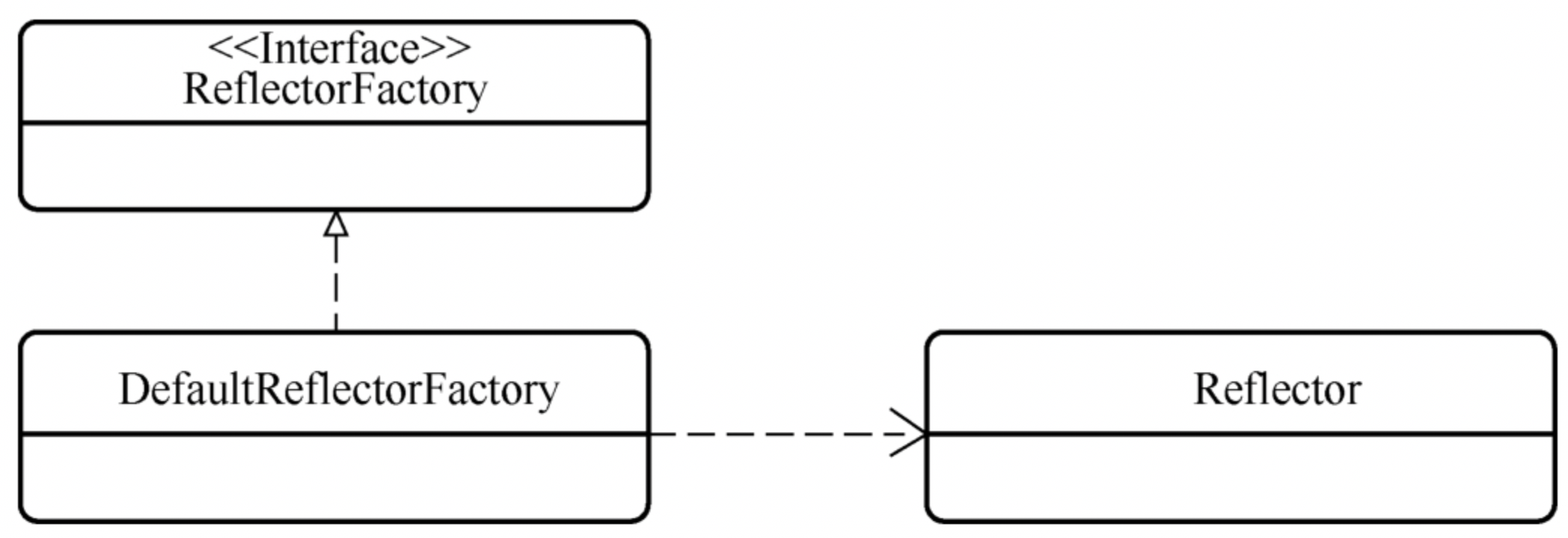
负责对一个类进行反射解析,并将解析后的结果储存起来,解析一个类的过程是用构造函数触发的,逻辑非常清晰

# 1.6、ExceptionUtil(异常拆包工具)
提供了一个拆包异常的工具方法unwrapThrowable,该方法将InvocationTargeException和UndeclaredThrowableException这两类异常进行拆包,得到其中真正的异常
# 1.7、ParamNameResolver(参数名解析器)
功能是按照顺序列出方法中的虚参,并对实参进行名称标注 主要涉及的是对字符串的处理
# 1.8、TypeParameterResolver(泛型参数解析器)
功能是帮助Mybatis推断出属性、返回值、输入参数中的泛型的具体类型 比如List\<\T> 中的这个T具体是什么类型,User? Map?等
对外提供了三个方法
- resolverFieldType 解析属性的泛型
- resolverReturnType 解析方法返回值的泛型
- resolverParamTypes 解析方法输入参数的泛型
核心方法resolverType
/**
* 解析变量的实际类型
* @param type 变量的类型
* @param srcType 变量所属于的类
* @param declaringClass 定义变量的类
* @return 解析结果
*/
private static Type resolveType(Type type, Type srcType, Class<?> declaringClass) {
if (type instanceof TypeVariable) { // 如果是类型变量,例如“Map<K,V>”中的“K”、“V”就是类型变量。
return resolveTypeVar((TypeVariable<?>) type, srcType, declaringClass);
} else if (type instanceof ParameterizedType) { // 如果是参数化类型,例如“Collection<String>”就是参数化的类型。
return resolveParameterizedType((ParameterizedType) type, srcType, declaringClass);
} else if (type instanceof GenericArrayType) { // 如果是包含ParameterizedType或者TypeVariable元素的列表
return resolveGenericArrayType((GenericArrayType) type, srcType, declaringClass);
} else {
return type;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 2、annotations包(注解包)
java注解是一种标注。 java中的类、方法、变量、参数、包等都可以被注解标注从而添加额外的信息
# 2.1、元注解
- @Target:用来声明注解可以用在什么地方,值需要在枚举中获取,包括:
- TYPE(类、接口、注解、枚举)
- FIELD(字段)
- METHOD(方法)
- PARAMETER(参数)
- CONSTRUCTOR(构造方法)
- LOCAL_VARIABLE(本地变量)
- ANNOTATION_TYPE(注解)
- PACKAGE(包)
- TYPE_PARAMTER(类型参数)
- TYPE_USE(类型使用)
- @Retention:用来声明注解的声明周期
- SOURCE:保留到源代码阶段,一般给编译器使用
- CLASS:保留到类文件阶段,这是默认的生命周期,JVM运行时不包含这些信息
- RUNTIME:保留到JVM运行时期
- @Documented:不需要设置具体的值,如果一个注解被Documented标注,则该注解会在javadoc中生成
- @Inherited:不需要设置具体的值,标识子类可以继承父类的该注解(只能继承,不能从接口继承)
- @Repeatable:表名该注解可以在同一个地方被重复使用
# 2.2、Param注解
 依赖开发工具可以找到Mybatis对于Param注解的解析是在ParamNameResolver构造方法中
依赖开发工具可以找到Mybatis对于Param注解的解析是在ParamNameResolver构造方法中

# 3、type包
type包中的类有55个之多,在遇到这种繁杂的情况时,一定要注意归纳总结 归纳总结是阅读源码中非常好的方法
type包中的类可以分为6组
- 类型处理器:1个接口、1个基础实现类、1个辅助类、43个实现类
- TypeHandler:类型处理器接口
- BaseTypeHandlerr:类型处理器的基础实现
- TypeReference:类型参考器
- **TypeHandler:43个类型处理器
- 类型注册表:3个
- SimpleTypeRegistry:基本类型注册表,内部使用Set维护了所有Java基本数据类型的集合
- TypeAliasRegistry:类型别名注册表,内部使用HashMap为了所有类型的别名和类型的映射关系
- TypeHandleRegistry:类型处理器注册表,内部维护了所有类型与对应类型处理器的映射关系
- 注解类:3个
- Alias:使用该注解可以给类设置别名
- MappedJdbcTypes:有时我们想使用自己的处理器来处理某些JDBC类型,只需创建BaseTypeHandler的子类,然后在上面加上该注解,声明它要处理的JDBC类型即可
- MappedTypes:有时我们想使用自己的处理器来处理某些java类型,只需要创建BaseTypeHandler的子类,然后在上面增加该注解,声明它要处理的Java类型即可
- 异常类:1个
- TypeException:表示与类型处理相关的异常
- 工具类:1个
- ByteArrayUtils:提供数组转化的工具方法
- 枚举类:1个
- JdbcType:在Enum中定义了所有的JDBC类型,类型来源于java.sql.Types
# 4、io包
完成mybatis中输入输出相关的操作
# 4.1、vfs
磁盘文件有很多种,FAT、VFAT、NFS、NTFS等,不同文件系统的读写操作各不相同,VFS作为一个虚拟的文件系统,可以屏蔽底层的操作差异,提供统一的操作接口 vfs的作用是在应用系统中寻找和读取资源文件
 vfs包中相关的类主要是3个
vfs包中相关的类主要是3个
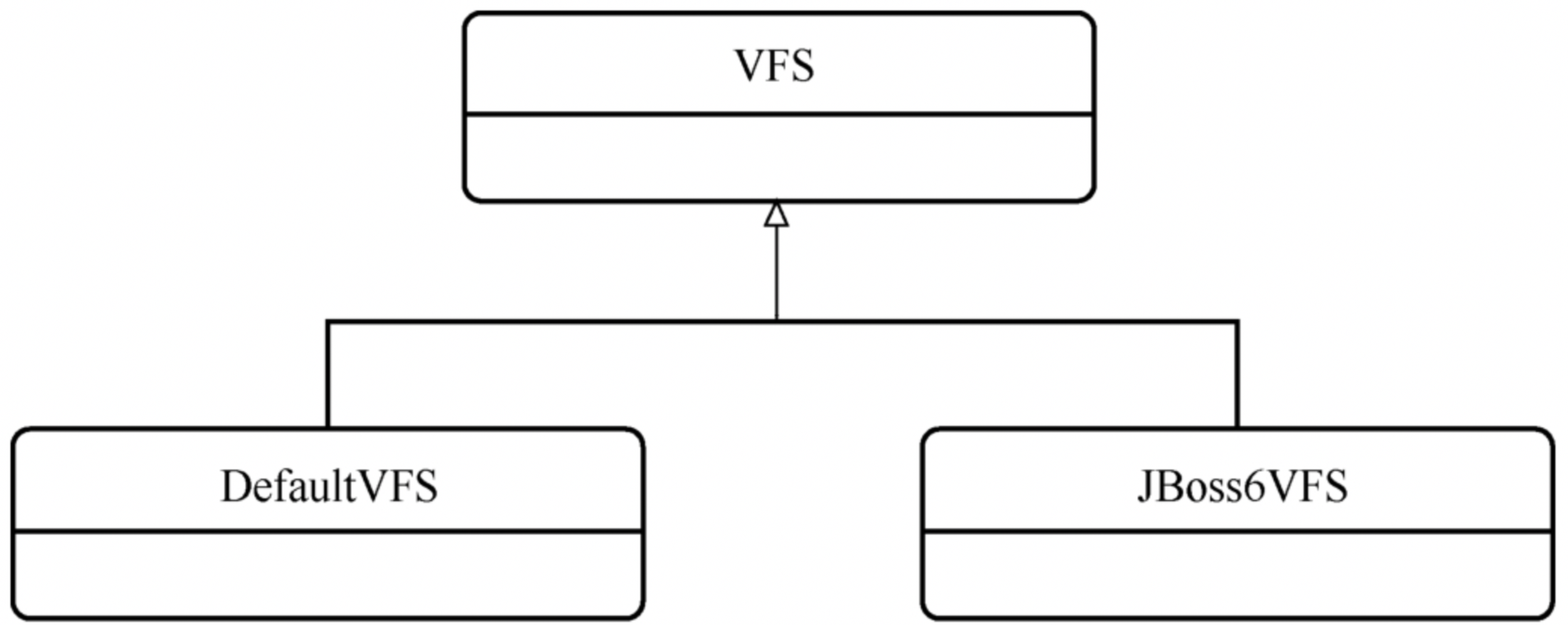 DefaultVFS:
DefaultVFS:
作为默认的VFS实现,isVaild函数恒返回true,因此只要加载DefauktVFS类,就一定能够通过VFS类中的VFSHolder单例中的校验,并且在进行类校验时,DefaultVFS在整个列表的最后,所以可以作为兜底方案
- list(URL,String):列出指定URL下符合条件的资源名称
- listResources(JarInputStream,String):列出给定jar包中符合条件的资源名称
- findJarForResource(URL):找出指定路径上的jar包,并返回jar包的准确路径
- getPackagePath(String):将jar包名称转为路径
- isJar:判断指定路径上是否是jar包
JBoss6VFS:
JBoss是基于J2EE的开源应用服务器
# 4.2、classLoaderWrapper(类加载)
要把文件加载成类,需要类加载器的支持 classLoaderWrapper内部封装了5种类加载器,这5中类加载器优先级由高到低,在读取类文件时,依次在5种类加载器中进行查找,查找到即返回结果

- 作为参数传入的类加载器,可能为null
- 系统默认的类加载器,未设置则为null
- 当前线程的线程上下文的类加载器
- 当前对象的类加载器
- 系统类加载器,在ClassLoaderWrapper构造方法中设置
classForName()
根据类名找出指定类的方法
# 4.3、ResolverUtil(工具类)
主要完成类的筛选,筛选条件可以是: 1、类是否是某个接口或者类的子类 2、类是否具有某个注解
# 5、logging(日志包)
# 5.1、日志等级:
- Fatal:致命等级的日志,发生了会导致应用程序退出的事件
- Error:错误等级的日志,发生了错误,但是不影响应用运行
- Warn:警告等级的日志,发生了异常,可能是潜在的错误
- Info:信息等级的日志,在一些粗粒度级别上需要强调的应用程序运行信息
- Debug:调试等级的日志,指一些细粒度的对于程序调试有帮助的信息
- Trace:跟踪等级的日志,指一些程序运行详细过程的信息
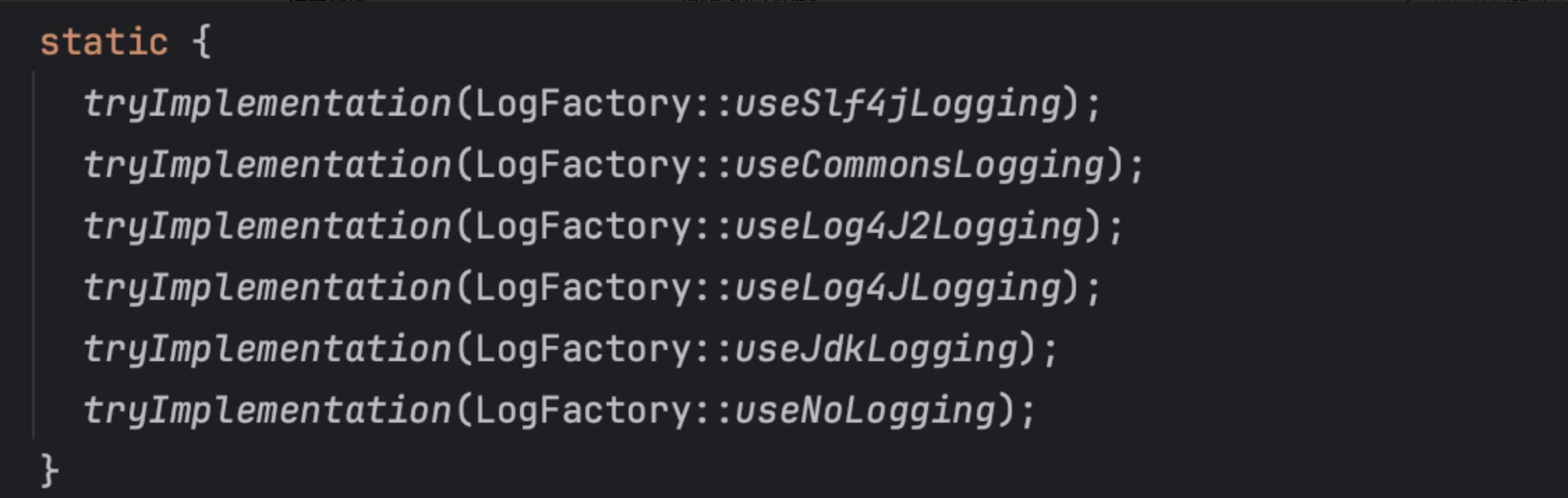
# 5.2、LogFactory
LogFactory生成目标对象的工作在静态代码块中被触发
# 5.3、jdbc
jdbc日志包存在的意义? Mybatis是ORM框架,负责数据库信息和java对象的互相映射,而不负责具体的数据库读写操作,具体的读写操作由JDBC完成,所以Mybatis的日志便不会包含JDBC的操作日志 但是有时候很多错误是JDBC导致的,因此JDBC日志是分析Mybatis框架报错的重要依据 JDBC日志有自己的输出体系,会给调试工作带来困难,所以jdbc子包就是为了解决这个问题
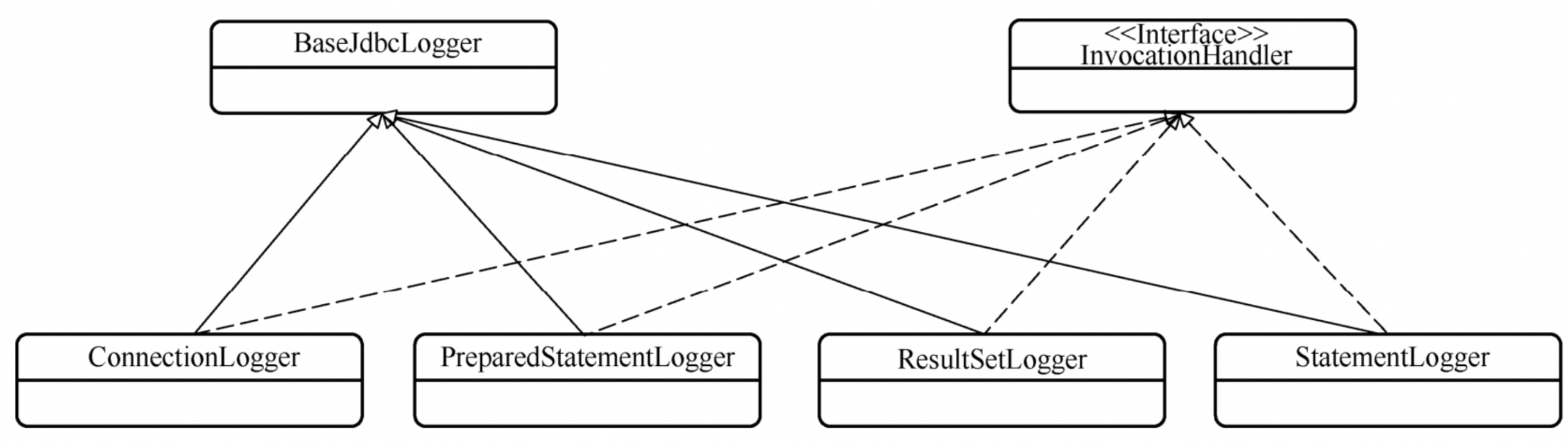 BaseJdbcLogger的各个子类使用动态代理来实现日志的打印,比如ConnectionLogger
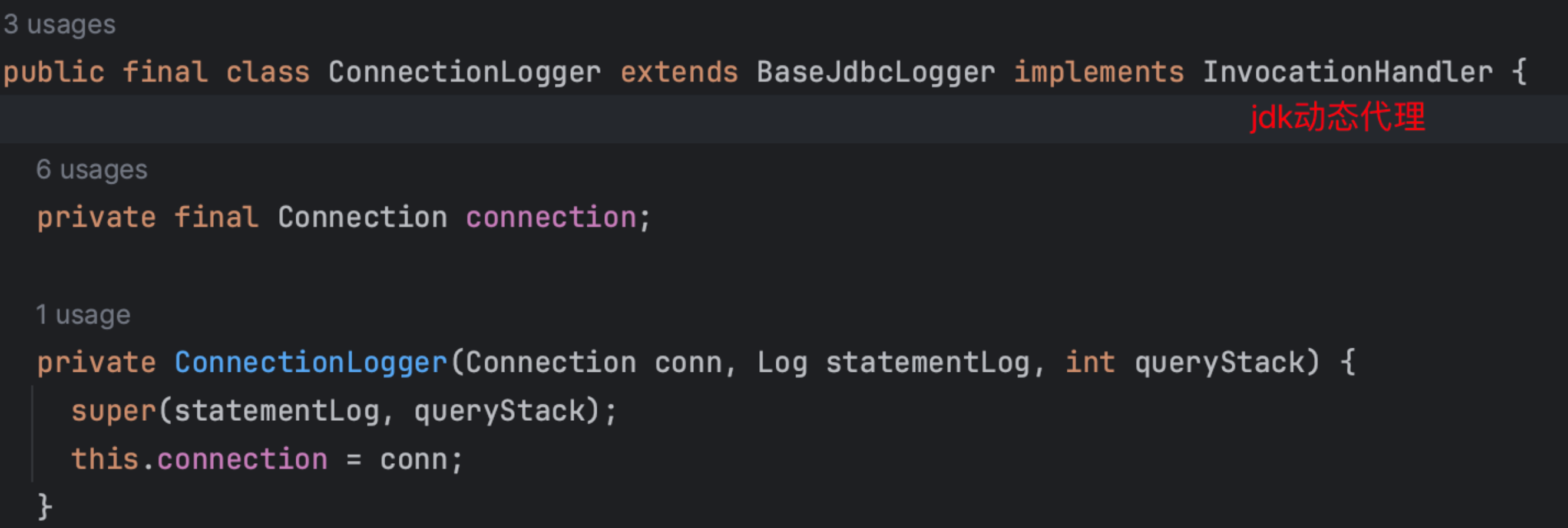
1、实现jdk动态代理
BaseJdbcLogger的各个子类使用动态代理来实现日志的打印,比如ConnectionLogger
1、实现jdk动态代理
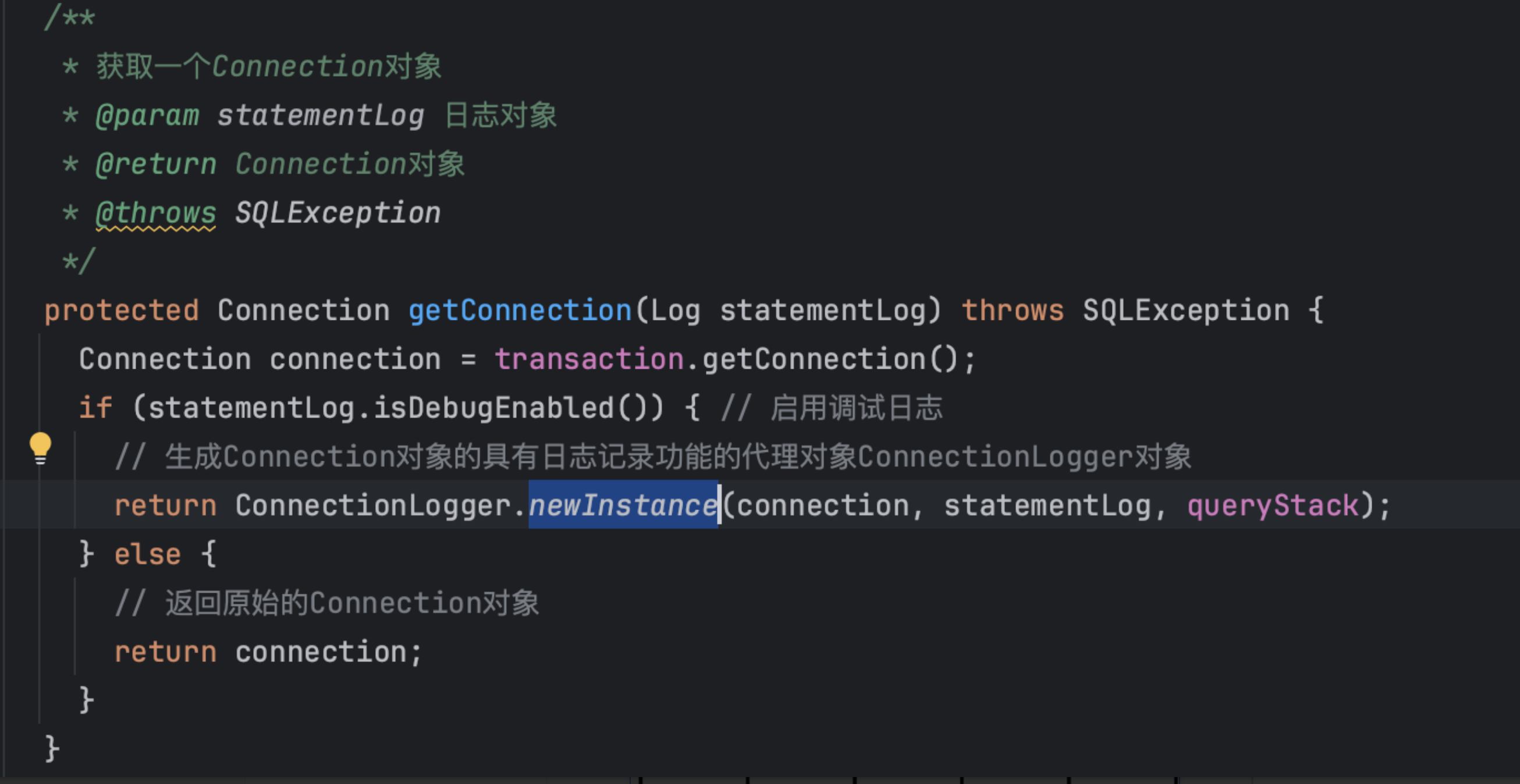
 2、BaseExecutor入口处调用ConnectionLogger生成代理对象
2、BaseExecutor入口处调用ConnectionLogger生成代理对象
 3、执行invoker方法,进行日志打印
3、执行invoker方法,进行日志打印
# 6、parsing包(XML解析)
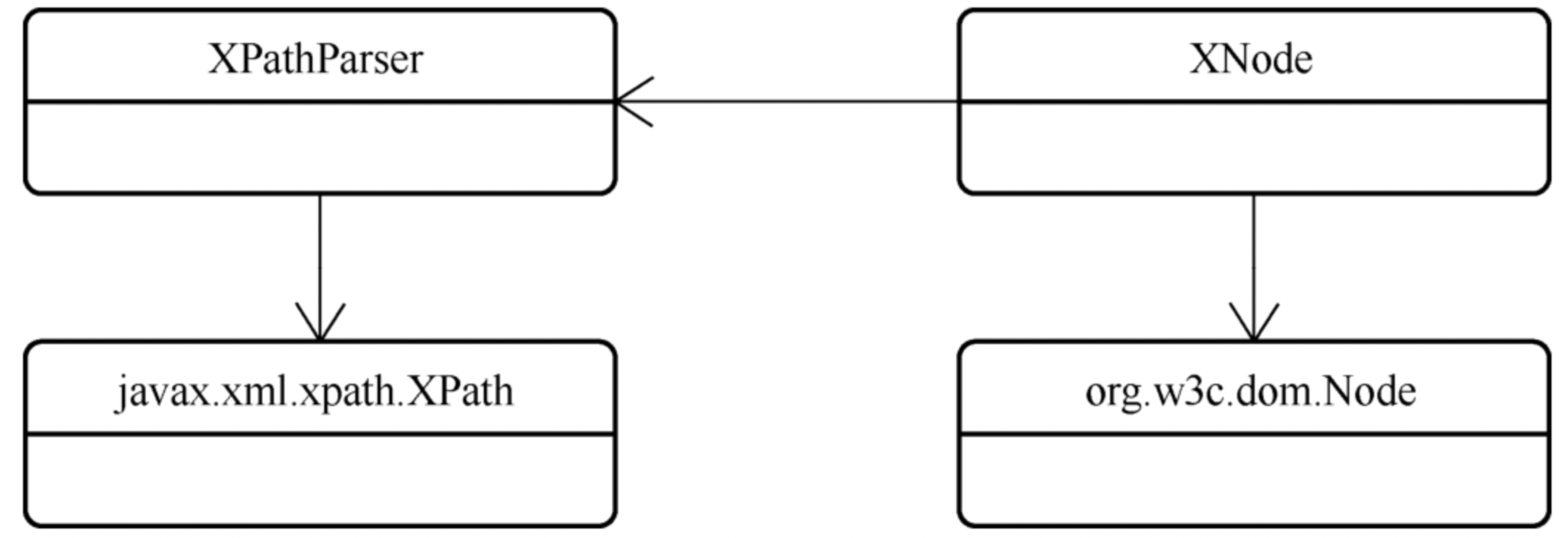
mybatis的配置文件和映射文件都是XML 在解析过程中,XPathParser 和 XNode是两个最为关键的类 XPathParser内部封装了XPath对象,XPath是解析XML的利器
# 6.1、GenericTokenParser
通用的占位符解析器,比如sql中的{} # $都是这个解析器进行解析替换 类中唯一一个parse方法,该方法主要完成占位符的定位工作,然后把占位符的替换工作交给与其关联的TokenHandler处理,
例如传入的参数是 openToken:"${" closeToken:"}" 向GenericTokenParser的parse方法传入的参数是"jdbc:mysql://127.0.0.1:3306/${dbname}" 则parse方法会将被"${" 和 "}"包围的dbname字符串解析出来,作为输入参数传入handler中的handleToken方法,然后用返回值替换${dbname}字符串
# 7、binding包(绑定关系)
主要用来处理java方法与SQL语句之间绑定关系的包 binding包维护了映射接口中方法和数据库操作节点之间的关联关系 1、维护映射接口中的抽象方法与数据库操作节点之间的关联关系 2、为映射接口中的抽象方法接入对应的数据库操作
# 7.1、数据库的接入
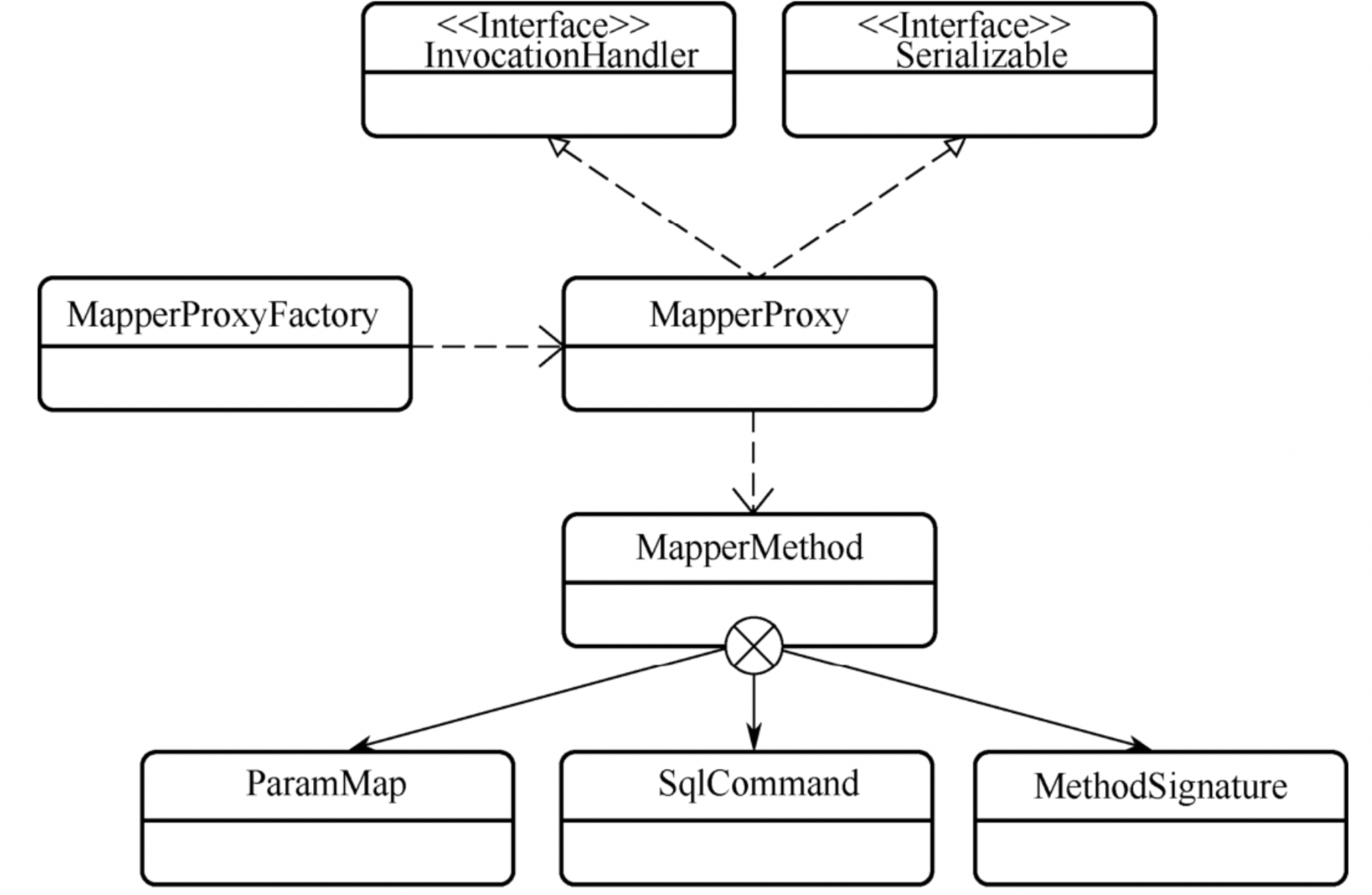
要想将一个数据库接入一个抽象方法中,首先要做的就是将一个数据库节点操作转化为一个方法,MapperMethod对象就表示数据库操作转化后的方法,每个MapperMethod对象都对应一个数据库操作节点,调用实例中的execute就可以触发节点中的SQL语句
MapperMethod:有两个属性(两个重要的内部类)
MethodSignature 方法签名(持有这个方法的详细信息)
SqlCommand sql语句(持有这个方法对应的SQL语句)

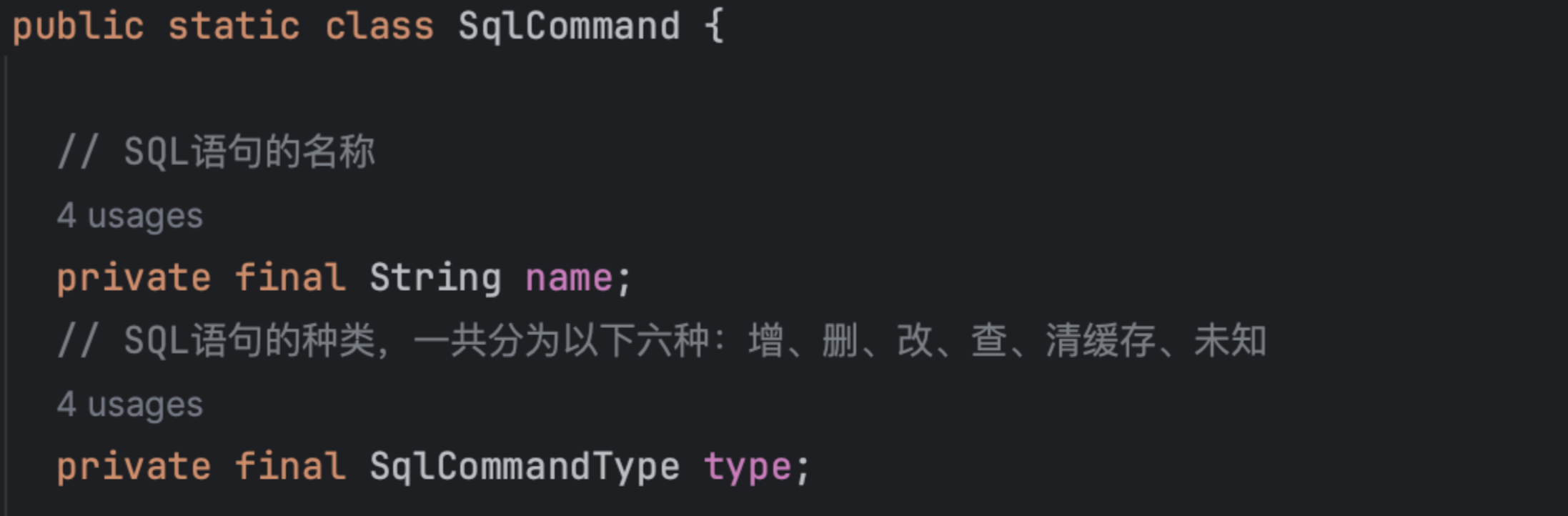
SqlCommand构造方法主要通过传入的参数完成name和type的赋值,其中的resolveMappedStatement子方法是一切的关键。
只要调用MapperMethod的execute就可以触发具体的数据库操作
# 7.2、数据库操作方法的接入
如何调用execute方法? 当调用映射接口中的方法时,java会去找接口 的实现类并执行该方法,但是映射接口是没有实现类的,为什么没有报错,而是去执行了MapperMethod的execute方法呢 答案就是动态代理MapperProxy
# 7.3、抽象方法与数据库操作节点的关联
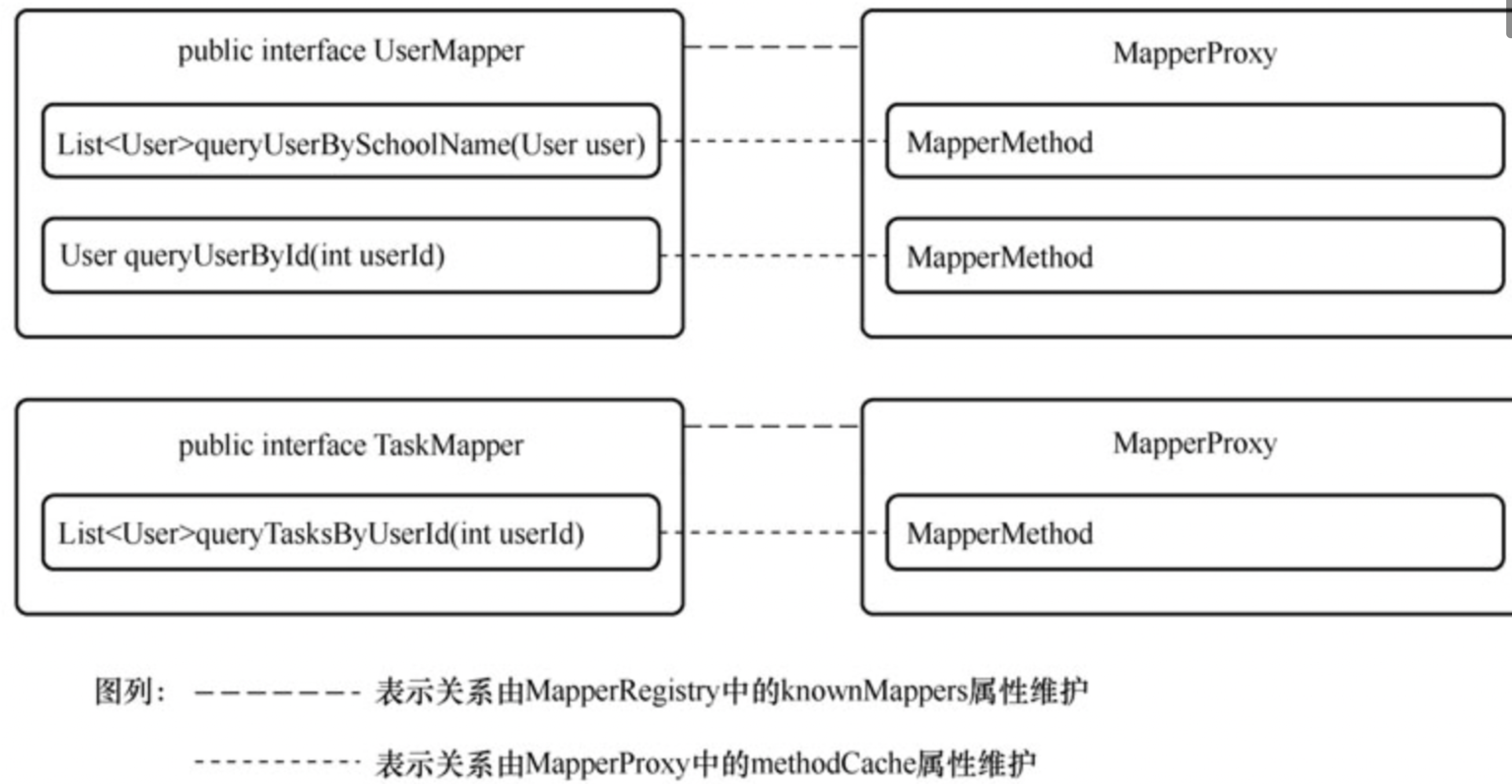
映射接口文件(xxxMapper.class)这么多,内置的抽象方法也很多,另一方面,映射文件(xxxMapper.xml)也很多,一切的对应关系怎么去维护呢?
Mybatis分两步解决了这个问题:
1、Mybatis将映射接口与MapperProxyFactory关联起来,这种关联关系是在MapperRegistry类的knownMappers属性中维护的
 MapperProxyFactory的构造方法只有一个参数,便是映射接口,并且其余属性不允许修改,所以只要MapperProxyFactory对象确定了,MapperProxy也就确定了,于是,MapperRegistry中的knownMappers属性间接的将映射接口与MapperProxy对象关联起来
2、此时的范围已经缩小到一个映射接口或者一个MapperProxy对象内,由MapperProxy内部的methodCache属性维护接口方法和MapperMethod对象的对应关系
MapperProxyFactory的构造方法只有一个参数,便是映射接口,并且其余属性不允许修改,所以只要MapperProxyFactory对象确定了,MapperProxy也就确定了,于是,MapperRegistry中的knownMappers属性间接的将映射接口与MapperProxy对象关联起来
2、此时的范围已经缩小到一个映射接口或者一个MapperProxy对象内,由MapperProxy内部的methodCache属性维护接口方法和MapperMethod对象的对应关系

通过这两步,生成的对应关系就如图所示
# 7.4、数据库操作接入总结
# 7.4.1、初始化阶段:
Mybatis在初始化阶段会进行各个映射文件的解析,然后将各个数据库操作节点的信息记录到Configuration对象的mappedStatements中(结构是一个StrictMap表示一个不允许覆盖键值的HashMap) 在初始化阶段,扫描所有的映射接口,并根据映射接口创建与之关联的MapperProxyFactory,两者的关联关系由MapperResigtry维护,当调用MapperRegistry的getMapper方法,就会通过MapperProxyFactory创建一个MapperProxy对象作为映射接口的代理
# 7.4.2、数据读写阶段
当映射接口有方法被调用时,会被代理对象MapperProxy劫持,触发MapperProxy内部的invoker方法,invoker方法会取出映射接口对应的MapperMethod对象 创建MapperMethod对象过程中,内部类SqlCommand的构造方法会去Configuratio对象的mappedStatements属性中根据当前映射接口名、方法名获取到前期已经存好的SQL语句 然后MapperMethod的execute方法被触发,方法内部会根据不同的SQL语句类型进行不同的数据库操作
# 8、builder包
# 8.1、建造者基类和工具类
BaseBuilder是所有建造者的基类
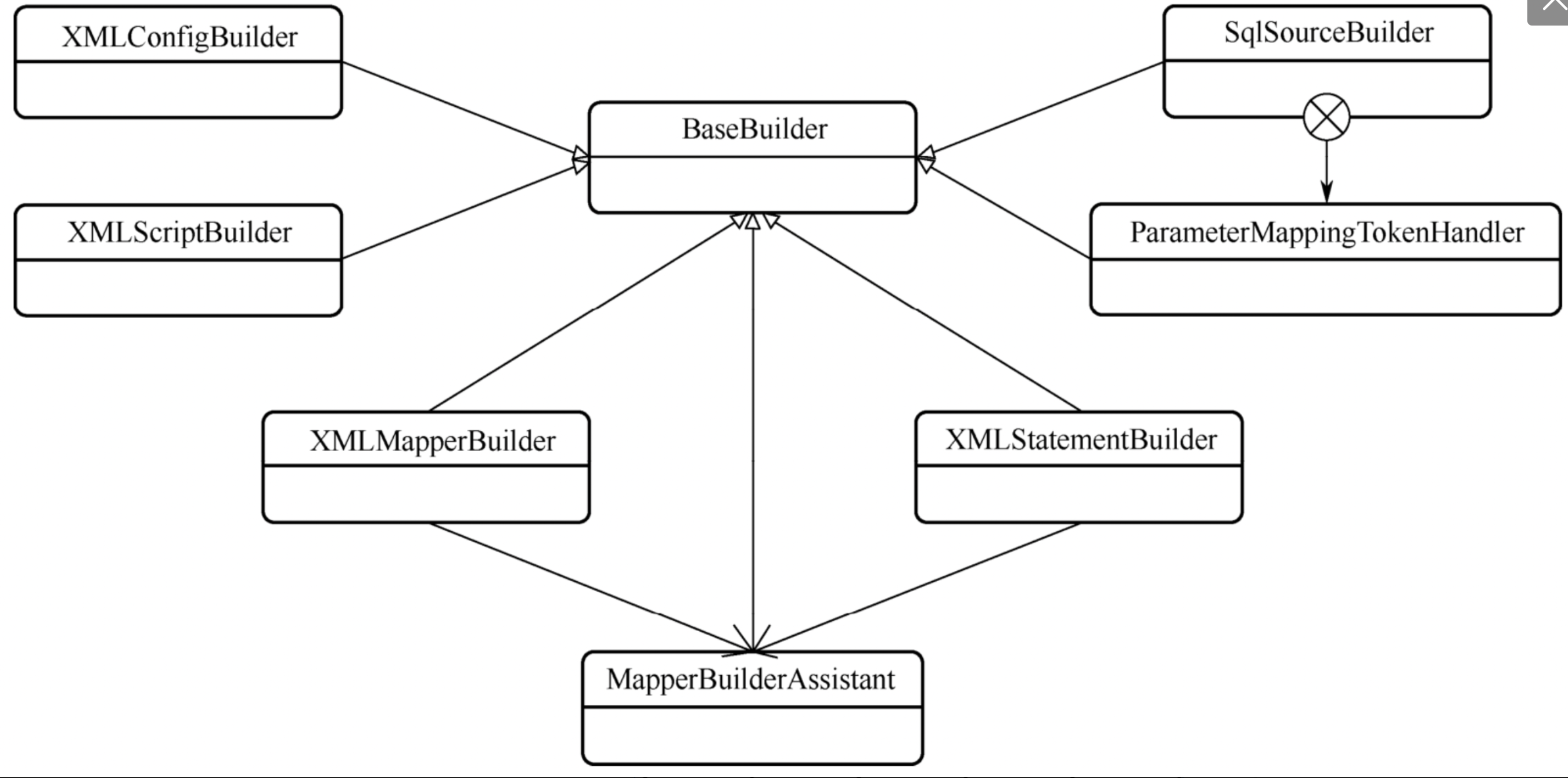 BaseBuilder类提供的工具方法大致分为以下几类:
BaseBuilder类提供的工具方法大致分为以下几类:
- **ValueOf:类型转化函数,负责将输入参数转化为指定的类型,并支持默认值设置
- resolve**:字符串转枚举类型函数,根据字符串找出对应的枚举类型并返回
- createInstance:根据类型别名创建类型实例
- resolverTypeHandle:根据类型处理器别名返回类型处理器实例
# 8.2、SqlSourceBuilder、StaticSqlSource
SqlSource是一个接口,有4种实现,通过parse方法生产出StaticSqlSource对象
准确的说,SqlSourceBuilder能够将DynamicSqlSource和RawSqlSource中的#$替换掉,从而将它们转化为StaticSqlSource
StaticSqlSource中的Sql语句已经不包含#{} ${},而是?,还有一个重要功能就是给出一个BoundSql对象

# 8.3、CacheRefResolver
mybatis支持多个namespace之间共享缓存,使用cache-ref标签,可以声明另一个namespace 如下所示,代表的含义是UserDao可以使用TaskDao的缓存
CacheRefResolver就是用来处理多个命名空间共享缓存的问题

# 8.4、ResultMapResolver
mybatis的resultMap标签允许继承,通过extends=xxxMap继承xxxMap设置的属性映射
 ResultMapResolver就是用来解析resultMap的继承关系
ResultMapResolver就是用来解析resultMap的继承关系
# 8.5、ParameterExpression(属性解析器)
用来将描述属性的字符串解析为键值对的形式
# 8.6、xml
xml包中一共有5个解析器,负责将xml文件解析成对应的类,每个类解析的范围如下图
- XMLMapperEntityResolver
- XMLConfigBuilder
- XMLMapperBuilder
- XMLStatementBuilder
- XMLIncludeTransformer
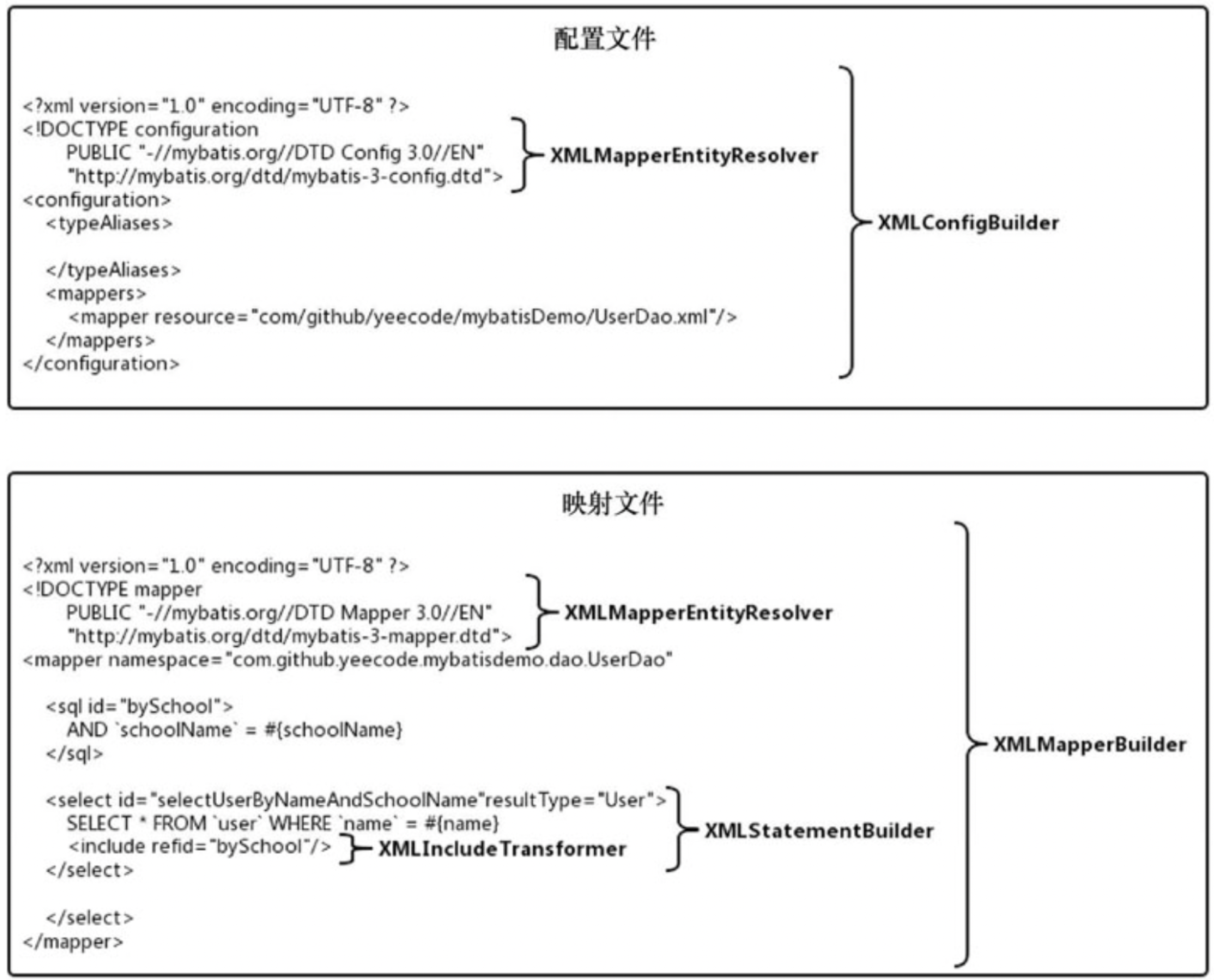
# 8.6.1、xml文件声明的解析
XML文件可以引用外部的DTD文件对XML文件进行校验,但是Mybatis有可能运行在无网络的环境中,无法联网下载DTD文件,针对于这种情况 XMLMapperEntityResolver就是解决这种问题的,在方法resolveEntity通过字符串匹配本地的DTD文件并返回
# 8.6.2、配置文件的解析
配置文件的解析是由XMLConfigBuilder负责的,同时解析之后构建出一个Configuration对象

# 8.6.3、数据库操作语句解析
映射文件的解析由XMLMapperBuilder负责
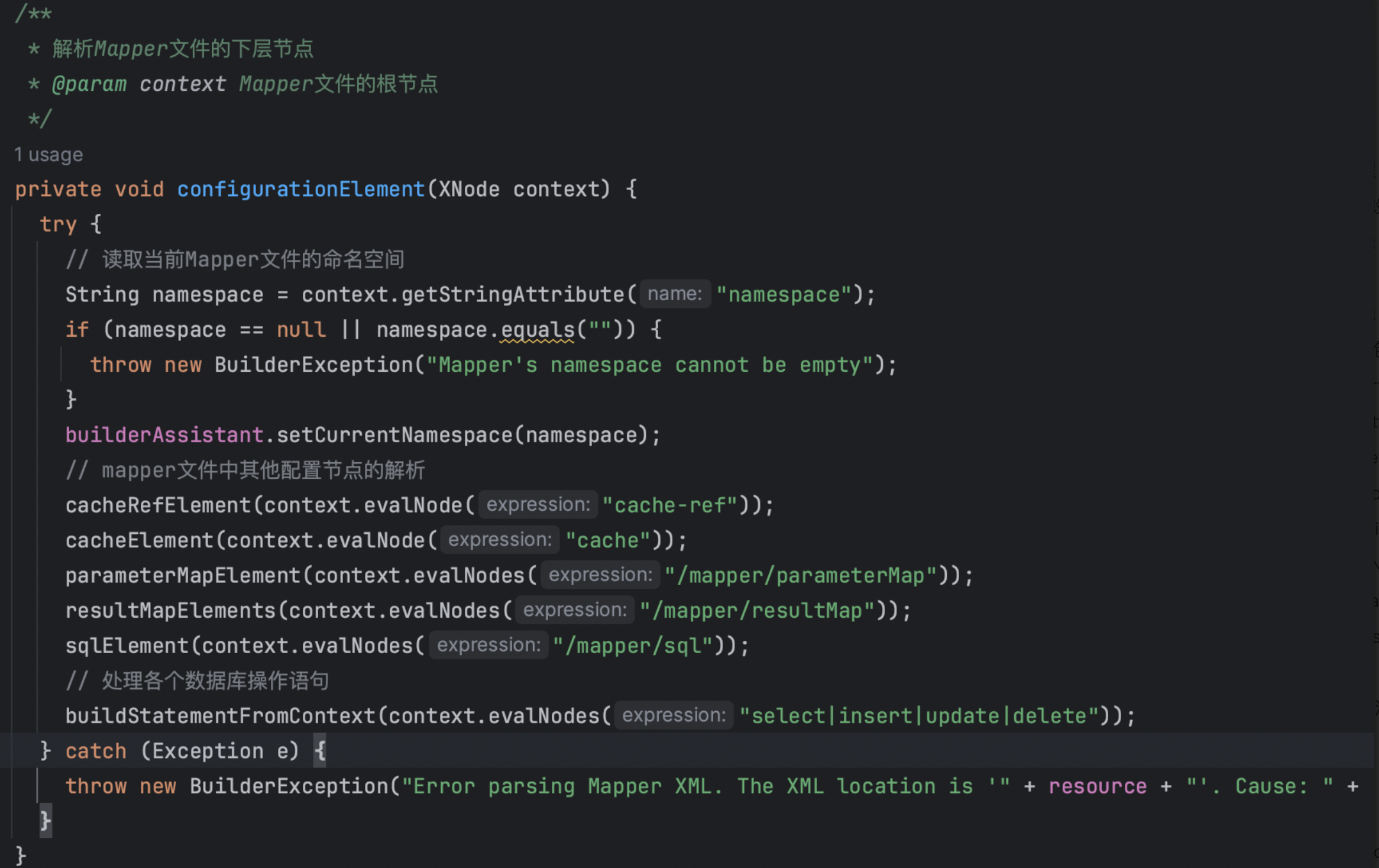 Q&A:
Q:解析过程中遇见循环依赖问题,Mybatis怎么解决的?比如解析xxxMapper中出现了extends属性,但是继承的属性还没有被解析,怎么办?
A:有两种解决方案
1、第一次全部解析,遇到错误先标记然后跳过,第二次只处理错误(Mybatis)
2、第一次解析只读如所有节点,但不处理依赖关系,然后在第二轮解析时只处理依赖关系(Spring)
Mybatis使用的第一种方式,Configuration中有一些属性转门记录临时性错误节点,在第二次解析时取出对应的属性值进行解析
Q&A:
Q:解析过程中遇见循环依赖问题,Mybatis怎么解决的?比如解析xxxMapper中出现了extends属性,但是继承的属性还没有被解析,怎么办?
A:有两种解决方案
1、第一次全部解析,遇到错误先标记然后跳过,第二次只处理错误(Mybatis)
2、第一次解析只读如所有节点,但不处理依赖关系,然后在第二轮解析时只处理依赖关系(Spring)
Mybatis使用的第一种方式,Configuration中有一些属性转门记录临时性错误节点,在第二次解析时取出对应的属性值进行解析
# 8.6.4、Statement解析
数据库操作节点(select、update、delete、insert)由XMLStatementBuilder完成
# 8.6.5、引用解析
对于\<\include refid="">节点的解析是XMLIncludeTransformer负责的,能够将标签中的include节点替换为被引用的SQL片段

# 8.6.6、注解映射的解析
builder包中的annotation包就是用来解析注解配置映射
 开发过程中可以在映射接口中的抽象方法增加注解的方式来声明数据库操作
开发过程中可以在映射接口中的抽象方法增加注解的方式来声明数据库操作

# 9、mapping包(解析实体类)
mapping包主要完成了下列功能:
- SQL语句处理功能
- 输出结果处理功能
- 输入参数处理功能
- 多数据库种类处理功能
- 其他功能
# 9.1、SQL语句处理功能
MappeddStatement:数据库操作节点(select、insert、)的所有内容
SqlSource:数据库操作标签包含的SQL语句
BoundSql:对于SqlSource的进一步处理

# 9.2、输出结果处理功能
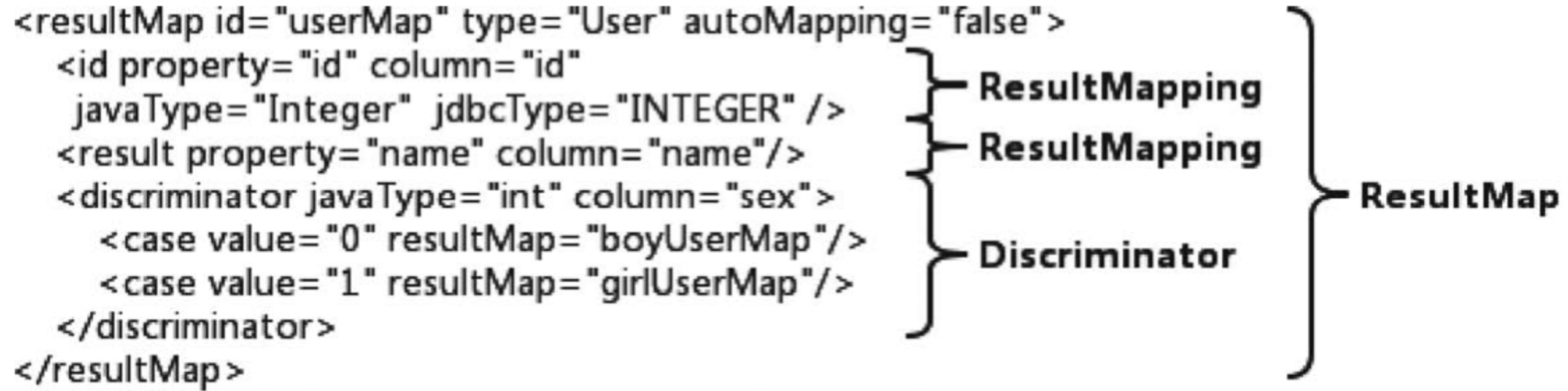
Mybatis在映射文件的数据库操作节点中,可以使用ResultType把结果直接转换为java对象,另外一种更灵活的方式是使用ResultMap来定义输出结果的映射方式
ResultMap的功能十分强大,支持输出结果的组装、判断、懒加载,例如下面的代码例子就是根据sex的不同输出不同的子类
 ResultMap标签的解析关系
ResultMap标签的解析关系
# 9.3、输入参数处理功能
可以将对象映射成SQL语句需要的输入参数,使用parameterMap
代码示例:

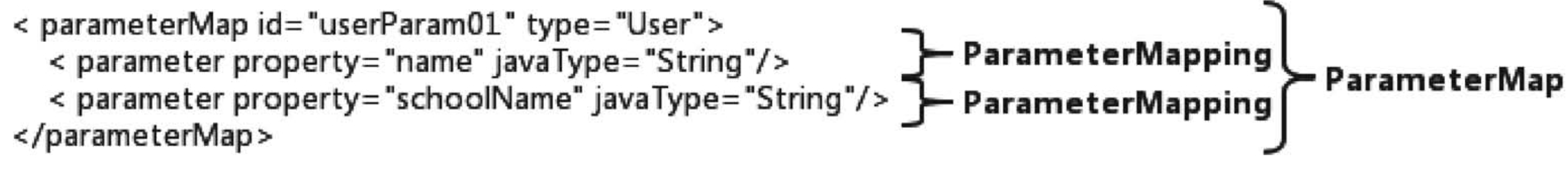
# 9.4、多数据库种类处理功能
mybatis支持多种数据库,需要在配置文件中先列举需要使用的数据库类型
配置文件设置数据库:
 然后在SQL语句对应数据库类型
然后在SQL语句对应数据库类型
 实现原理:
多数据支持的实现由DatabaseIdProvider接口负责,有一个子类VendorDatabaseIdProvider,主要方法是setProperties和getDatabaseId
setProperties方法:将Mybatis配置文件中设置在databeseIdProvider节点中的信息写入VendorDatabaseIdProvider对象中
getDataBaseId方法:给出当前传入的datasource对象对应的databaseId,主要逻辑在getDatabaseName方法中
实现原理:
多数据支持的实现由DatabaseIdProvider接口负责,有一个子类VendorDatabaseIdProvider,主要方法是setProperties和getDatabaseId
setProperties方法:将Mybatis配置文件中设置在databeseIdProvider节点中的信息写入VendorDatabaseIdProvider对象中
getDataBaseId方法:给出当前传入的datasource对象对应的databaseId,主要逻辑在getDatabaseName方法中
# 10、scripting包
SQL脚本中可以编写if、foreach、where等条件标签,这些标签的解析主要由scripting包完成的
# 10.1、OGNL
是一种功能强大的表达式语言,通过它,能够完成从集合中选取对象、读写对象的属性、调用对象和类的方法、表达式求值和判断等操作 OGNL有java工具包,只要引入就可以在java中使用OGNL功能
OGNL的三个重要概念:
- 表达式(expression):是一个带语法含义的字符串,是整个OGNL的核心内容,通过表达式来确定需要进行的OGNL操作
- 根对象(root):可以理解为OGNL的被操作对象,表达式中的操作就是针对这个对象展开的
- 上下文(context):整个OGNL处理的上下文环境,是一个Map对象
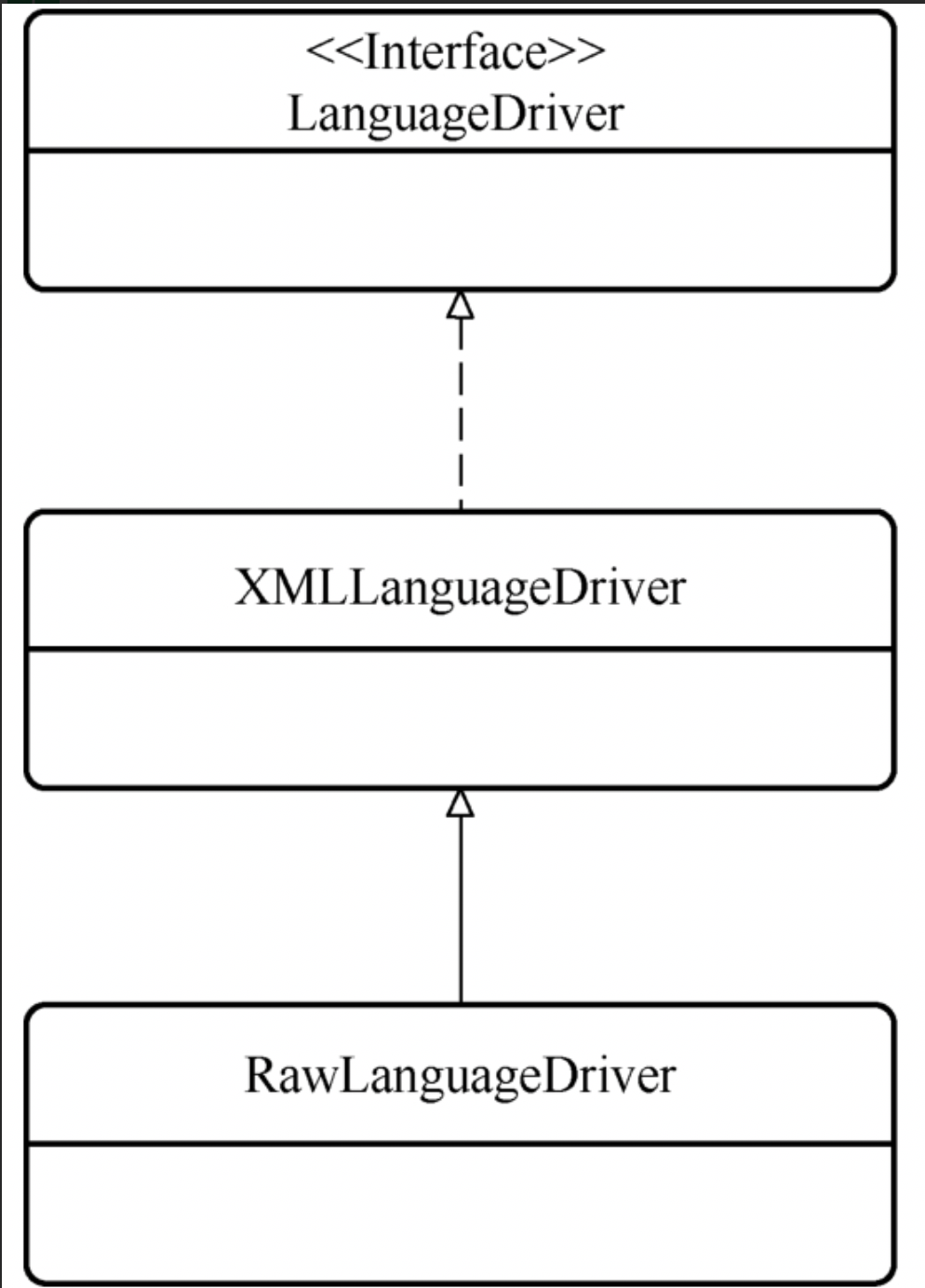
# 10.2、languageDriver
语言驱动类的接口,有两个默认实现,XMLLanguageDriver和RawLanguageDriver
# 10.3、XMLScriptBuilder
映射文件中的语句有很多sql标签组成的一棵树,要想解析这颗树,首先需要将xml内容读取出来,然后在内存中构建SQL节点树,SQL节点树的构建由XMLScriptBuilder完成。
内部含有接口NodeHandle,每个SQL节点都有一个NodeHandle的实现,SQL节点和对应的Handle实现类的对应关系由nodeHandleMap维护
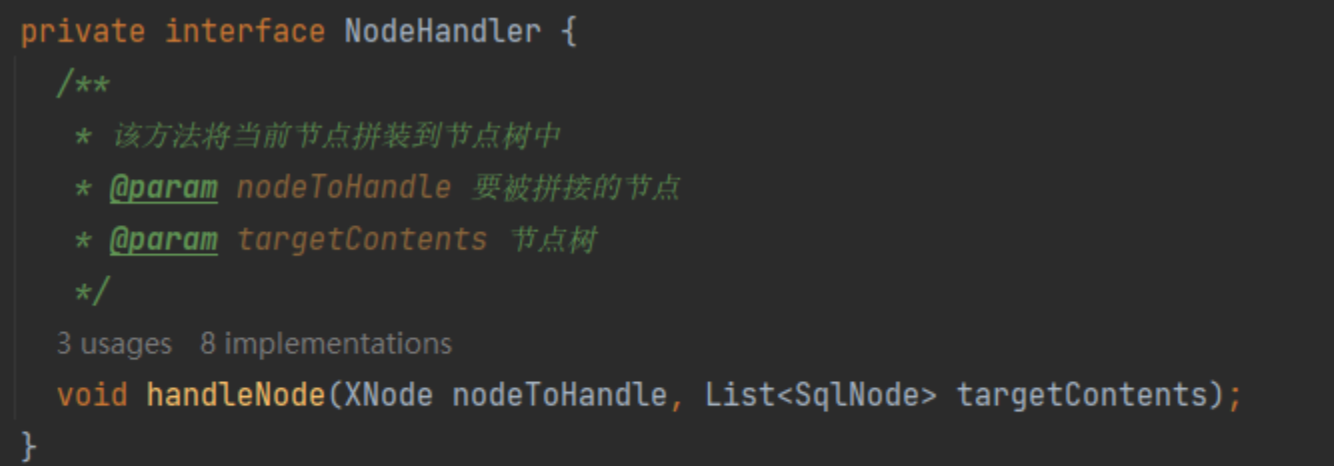 

# 10.4、xmltags
SQL节点树的解析
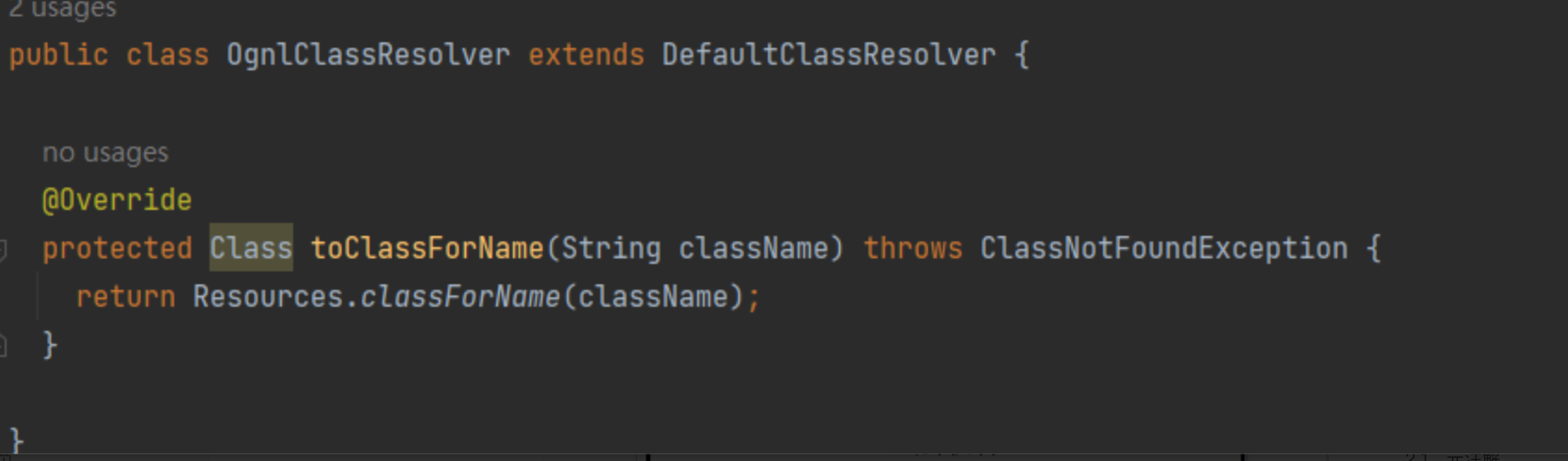
OgnlClassResolver:DefaultClassResolver 类是 OGNL 中定义的一个类,OGNL 可以通过该类进行类的读取,即将类名转化为一个类
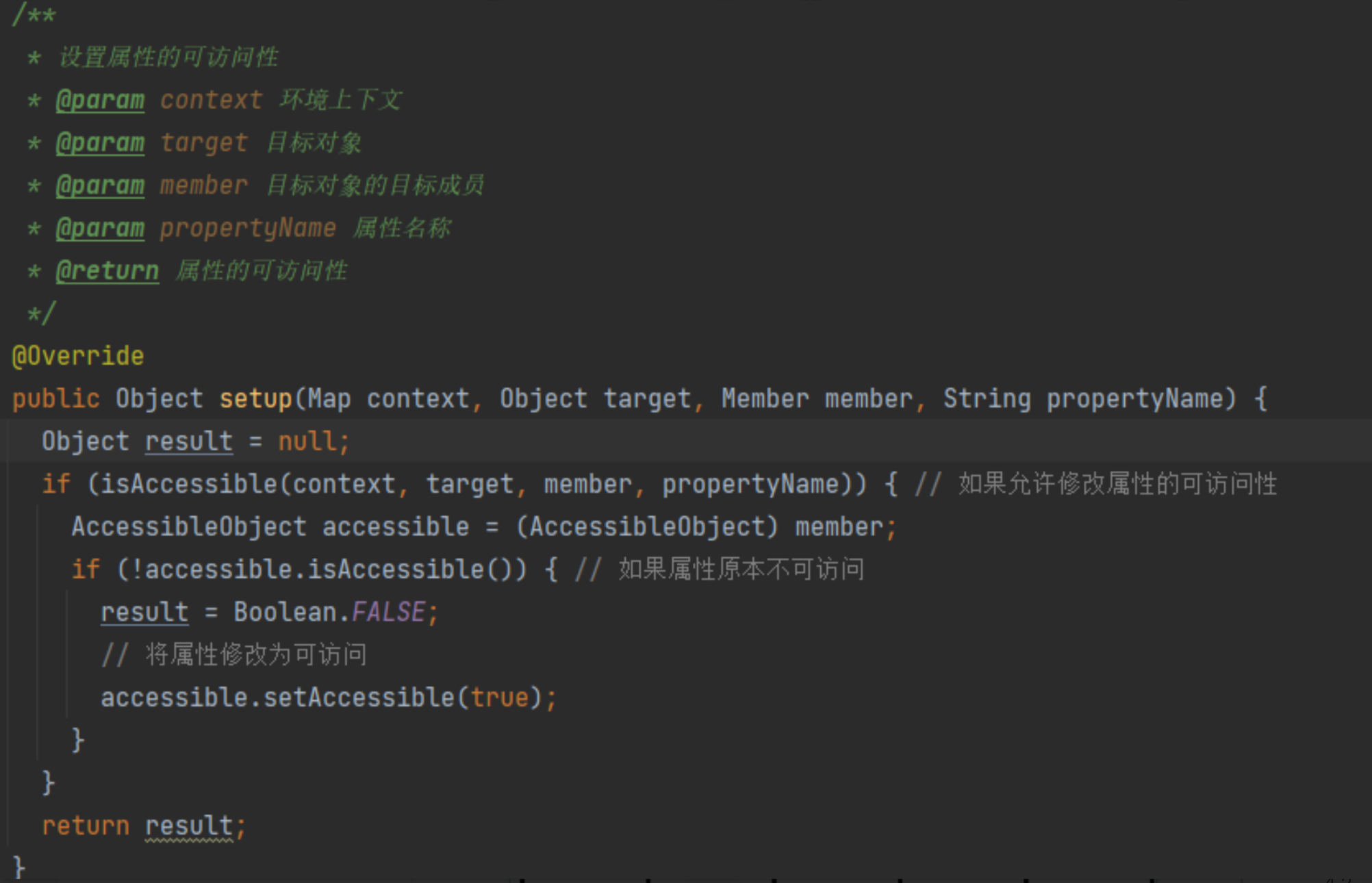
 OgnlMemberAccess:OGNL借助这个接口为访问的对象的属性做好准备
OgnlMemberAccess:OGNL借助这个接口为访问的对象的属性做好准备
 OgnlCache:为了提升效率,做的一个缓存,对表达式进行预解析
OgnlCache:为了提升效率,做的一个缓存,对表达式进行预解析
# 10.5、ExpressionEvaluator(表达式求值器)
mybatis并没有把OGNL直接暴露给各个SQL节点使用,而是对OGNL进行更易用性的封装,对外暴露了ExpressionEvaluator类(表达式求值器)
提供了两个方法
- evaluateBoolean:能够对true或者false形式的表达式求值,例如if节点
- evaluateIterable:能够对结果是迭代形式的表达式进行求值,例如foreach
# 10.6、DynamicContext(动态上下文)
一方面,在进行SQL树的解析时,需要不断的保存已经解析完成的SQL片段; 另一方面,在进行SQL节点树的解析时,也需要一些参数和环境信息,作为解析的依据 以上的两个功能就是由动态上下文来提供的
根据构造方法可以清楚的看出上下文环境是如何被创建出来的:
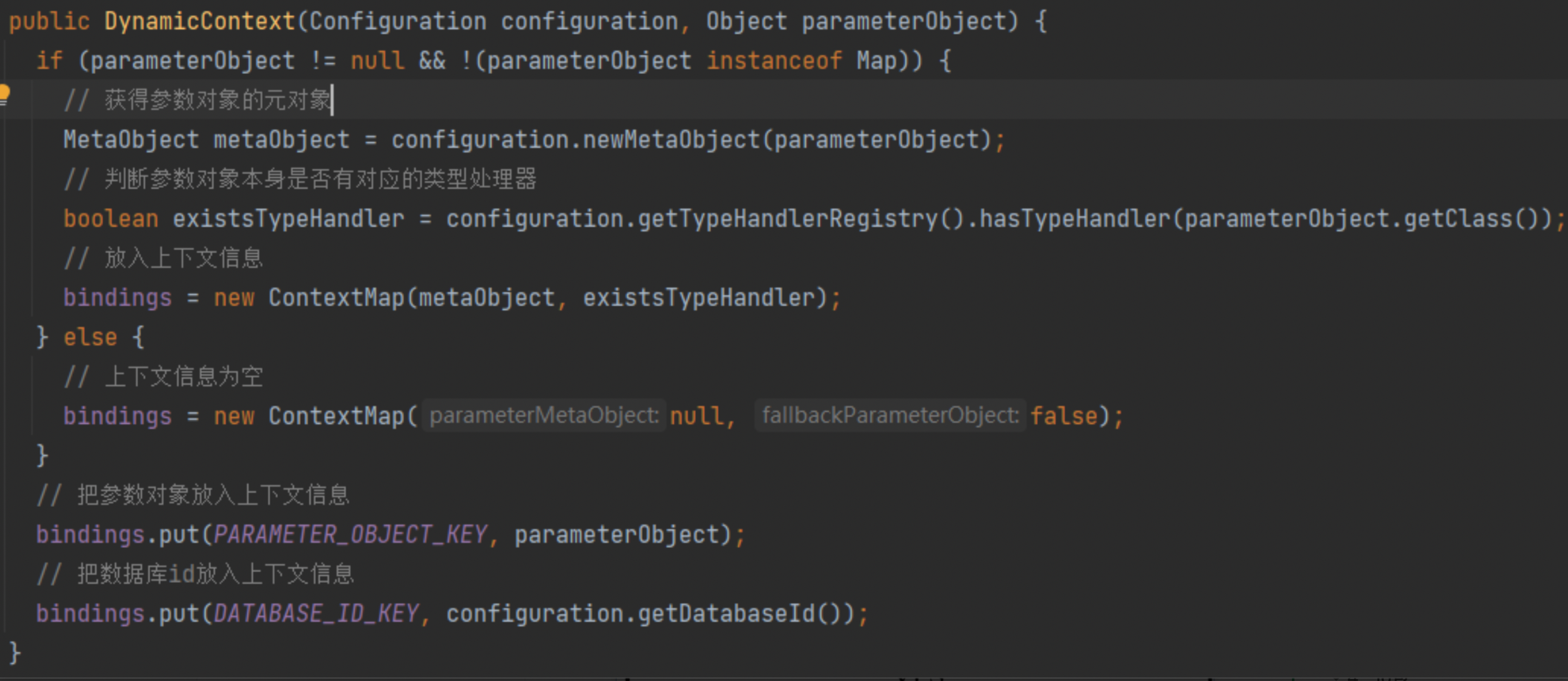 上下文的bindings中存储了如下信息:
上下文的bindings中存储了如下信息:
- 数据库id,因此在编写SQL语句时,我们可以直接使用DATABASE_ID_KEY引用数据库id的值
- 参数对象,在编写SQL语句时,可以直接使用PARAMETER_OBJECT_KEY变量来引用整个参数对象
- 参数对象的元数据,基于参数对象的元数据可以方便的引用参数对象的属性值,因此在编写SQL语句时可以直接引用参数对象的属性
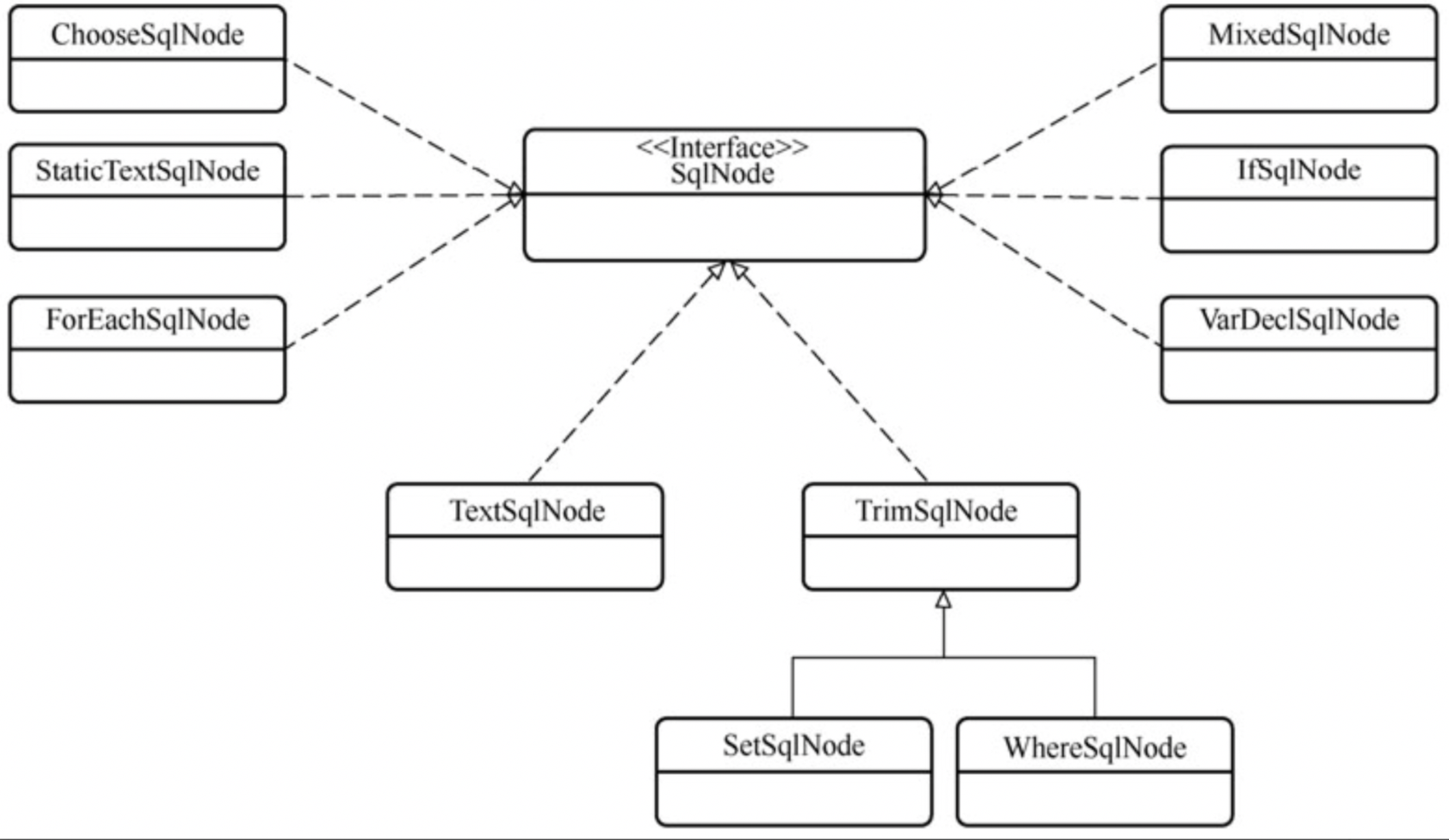
# 10.7、SqlNode
SqlNode是一个接口,其中只定义了一个apply方法,该方法负责完成自身节点的解析,并将解析结果合并到输入参数提供的上下文环境中 编写的if where这些标签对应的就是一个SqlNode,分别对应IfSqlNode和WhereSqlNode
# 11、datasource包(数据源)
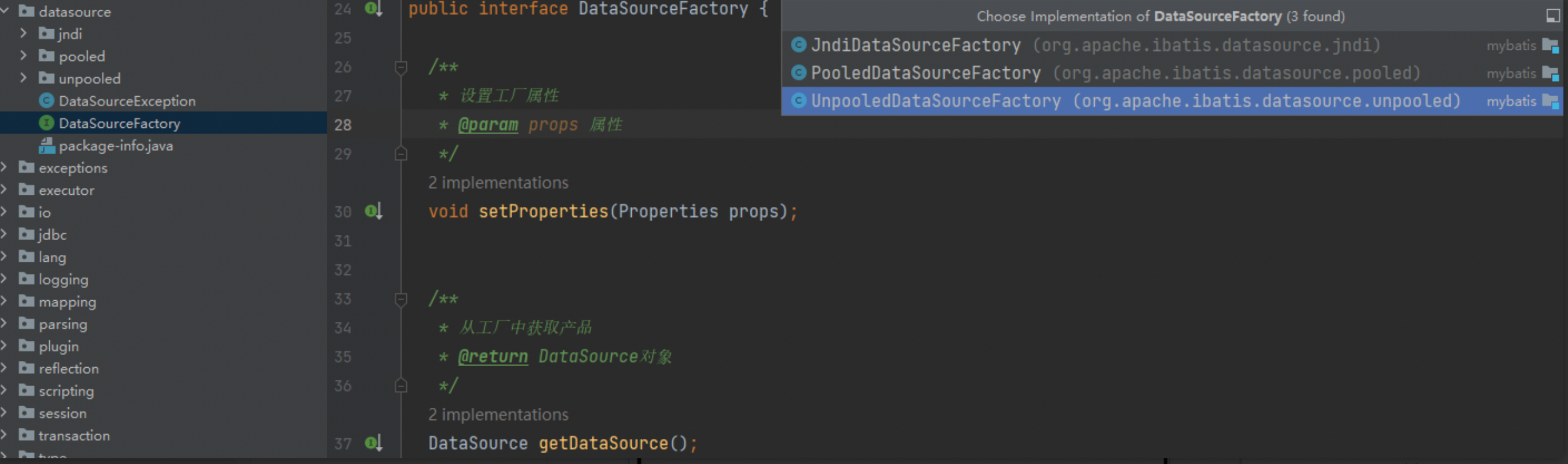
# 11.1、DataSourceFactory数据源工厂接口
mybatis是根据datasource的type属性进行工厂的选择

# 11.2、JndiDataSourceFactory
JNDI(Java Naming and Directory Interface)java命名和目录接口 能够为java程序提供命名和目录访问的接口,可以理解为一个命名规范,在使用该规范为资源命名并放入环境(context)中,我们可以根据名称从环境中查找(lookup)对应的资源 JndiDataSourceFactory的作用就是从环境中找出指定的 JNDI数据源
在mybatis中使用JNDI:

- initial_context:起始环境信息,Mybatis会在这里寻找指定的数据源,如果不设置,Mybatis会在整个环境中寻找数据源
- data_source:数据源名称
# 11.3、UnpooledDataSourceFactory
非池化数据源工厂,需要真正的创建一个数据源,不过创建过程很简单,直接在构造方法中创建数据源对象,并保存在自身的成员变量中,
 非池化数据源是最简单的数据源,只需要在每次请求连接时打开连接,在每次连接结束时断开连接
在Mybatis中使用UNPOOLED来代表非池化数据源
非池化数据源是最简单的数据源,只需要在每次请求连接时打开连接,在每次连接结束时断开连接
在Mybatis中使用UNPOOLED来代表非池化数据源

# 11.4、PooledDataSourceFactory
池化数据源,在连接池中总保留一定数量的数据库连接以备使用,可以在需要时取出,用完后放回,减少连接的创建和销毁工作,提升整体的效率
 PooledDataSource:
PooledDataSource:
- state:是一个PoolSate对象,存储了所有的数据库连接和状态信息,在类属性中,使用idleConnections和activeConnections两个列表存储了所有的空余连接和活跃连接,除此之外,还有大量的属性来存储连接池运行过程中的统计信息
- dataSource:当池化的数据源在连接池中的连接不够时,也需要创建新的连接,dataSource属性是一个UnPooledDataSource对象
- expectedConnectionTypeCode:一个数据源连接池必须确保池中的每个连接都是等价的,这样才能确保我们每次从连接池中取出连接不会存在差异。该属性存储的该数据源连接类型编码
# 11.5、池化连接的给出和收回
- 给出池化连接:方法是popConnection,方法的伪代码总结如下图

- 收回池化连接,方法pushConnection

# 11.6、PooledConnection
池化连接,当我们要关闭一个池化连接时,它不应该真正的被关掉,而是应该将自己放回连接池,所以,通过PooledDataSource获取的数据库连接,不能是普通的Connection对象
pooled子包中存在一个PooledConnection对象,是对普通Connection对象的代理,其中一个重要工作就是修改Connection类的close方法的行为

# 12、jdbc包
该包提供了数据库操作语句的能力和脚本运行能力
# 12.1、AbstractSQL
抽象类,含有一个抽象方法getSelf 包含两个静态内部类SafeAppendable 、 SQLStatement
SafeAppendable: 是一个拼接器,append方法能实现串的拼接功能 SQLStatement: 可以完整的表述出一条SQL语句
# 12.2、SqlRunner
可以直接执行SQL语句的工具类 SqlRunner可以接受SQL语句和参数,然后执行数据库操作,不过并不能完成对象和SQL参数、结果等的对象映射

# 12.3、ScriptRunner
可以直接执行脚本的工具类,开发者可以直接把整个脚本文件交给Mybatis执行

# 13、cache包
cache包是典型的装饰器模式的应用案例,在imple子包存放了实现类,在decorators子包中存放了众多装饰器类,而cache接口是实现类和装饰器类的共同接口

# 13.1、CacheKey缓存键
Mybatis每秒过滤众多的数据库查询操作,这对Mybatis缓存键的设计提出了很高的要求,必须满足一下几点
- 无碰撞:必须保证两个不同的查询请求生成的键不一致,
- 高效比较:每次缓存查询操作都可能会引发键之间的多次比较,因此该操作必须是高效的
- 高效生成:每次缓存查询和写入操作都需要生成缓存的键,因此该操作也必须是高效的
缓存键的生成:
在数据库查询时,会根据当前的查询条件生成一个CacheKey,在BaseExecutor中可以看到这个过程

# 13.2、PerpetualCache
缓存的实现类,只有两个属性 id:用来标识一个缓存,一般使用映射文件的namespace作为缓存的id,这样能保证不同的映射文件的缓存是不同的 cache:是一个hashMap,采用键值对的形式来存储数据
# 13.3、缓存装饰器
decorators包下存在很多的装饰器,根据装饰器的功能可以将他们分为几个大类
- 同步装饰器:为缓存增加同步功能 如SynchronizedCache
- 日志装饰器:为缓存增加日志功能 如LoggingCache
- 清理装饰器:为缓存中的数据增加清理功能,如FifoCache,LruCache
- 阻塞装饰器:为缓存增加阻塞功能,如BlockingCache
- 定时清理装饰器:为缓存增加定时刷新功能,如ScheduledCache
- 序列化装饰器:为缓存增加序列化功能,如SerializedCache
- 事务装饰器:用于支持事务操作的装饰器,如TransactionCache
# 13.3.1、同步装饰器
在Mybatis使用过程中,可能会出现多个线程同时访问一个缓存的情况,例如下图代码所示,如果多个线程同时调用selectUsers方法,而缓存实现类PerpetualCache并没有增加任何多线程的保护措施,会引发线程安全问题,而Mybatis将这项工作交给了SynchronizedCache,它的实现非常简单,在被包装的对象方法外围增加Synchronized关键字,使得方法编程同步方法

# 13.3.2、日志装饰器
为数据库操作增加缓存的目的是减少数据库的查询操作从而提高运行效率。而缓存的配置也非常重要,如果配置过大则浪费内存空间,如果配置过小则无法更好地发挥作用。因此,需要依据一些运行指标来设置合适的缓存大小。
日志装饰器可以为缓存增加日志统计的功能,而需要统计的数据主要是缓存命中率。所谓缓存命中率是指在多次访问缓存的过程中,能够在缓存中查询到数据的比率。
日志装饰器的实现非常简单,即在缓存查询时记录查询的总次数与命中次数

# 13.3.3、清理装饰器
虽然缓存能够极大地提升数据查询的效率,但这是以消耗内存空间为代价的。 缓存空间总是有限的,因此为缓存增加合适的清理策略以最大化地利用这些缓存空间十分重要。 缓存装饰器中有四种清理装饰器可以完成缓存清理功能,这四种清理装饰器也对应了MyBatis的四种缓存清理策略
- FifoCache装饰器:采用先进先出的策略来清理缓存,它内部使用了 keyList属性存储了缓存数据的写入顺序,并且使用 size属性存储了缓存数据的数量限制。当缓存中的数据达到限制时,FifoCache装饰器会将最先放入缓存中的数据删除
- LruCache装饰器:即近期最少使用算法,该算法会在缓存数据数量达到设置的上限时将近期未使用的数据删除。LruCache 装饰器便可以为缓存增加这些功能
- WeakCache装饰器:通过将缓存数据包装成弱引用的数据,从而使得 JVM可以清理掉缓存数据
- SoftCache装饰器:SoftCache 装饰器和 WeakCache 装饰器在结构、功能上高度一致,只是从弱引用变成了软引用
# 13.3.4、阻塞装饰器
当 MyBatis 接收到一条数据库查询请求,而对应的查询结果在缓存中不存在时,MyBatis会通过数据库进行查询。试想如果在数据库查询尚未结束时,MyBatis又收到一条完全相同的数据库查询请求,那应该怎样处理呢?常见的有以下两种方案。
- 因为缓存中没有对应的缓存结果,因此再发起一条数据库查询请求,这会导致数据库短时间内收到两条完全相同的查询请求。·
- 虽然缓存中没有对应的缓存结果,但是已经向数据库发起过一次请求,因此缓存应该先阻塞住第二次查询请求。等待数据库查询结束后,将数据库的查询结果返回给两次查询请求即可。
显然,后一种方案更为合理。阻塞装饰器 BlockingCache 为缓存提供了上述功能

# 13.3.5、定时清理装饰器
当调用缓存的 clear方法时,会清理缓存中的数据。但是该操作不会自动执行。 定时清理装饰器 ScheduledCache则可以按照一定的时间间隔来清理缓存中的数据,即按照一定的时间间隔调用 clear方法
# 13.3.6、序列化装饰器
有些场景下,我们不想让外部的引用污染缓存中的对象。这时必须保证外部读取缓存中的对象时,每次读取的都是一个全新的拷贝而不是引用。 序列化装饰器SerializedCache为缓存增加了这一功能。在使用 SerializedCache后,每次向缓存中写入对象时,实际写入的是对象的序列化串;而每次读取对象时,会将序列化串反序列化后再返回。 通过序列化和反序列化的过程保证了每一次缓存给出的对象都是一个全新的对象,对该对象的修改不会影响缓存中的对象。 当然,这要求被缓存的数据必须是可序列化的,否则SerializedCache会抛出异常
# 13.4、缓存的组建
组建缓存的过程就是根据需求为缓存的基本实现增加各种装饰的过程,该过程在CacheBuilder中完成
 在映射文件中,我们可以通过如下所示的片段指定缓存的特性
在映射文件中,我们可以通过如下所示的片段指定缓存的特性

# 13.5、事务缓存
在数据库操作中,如果没有显式地声明事务,则一条语句本身就是一个事务。在查询语句进行数据库查询操作之后,相应的查询结果可以立刻放入缓存中备用。
那么,事务中的语句进行数据库查询操作之后,相应的查询结果可以立刻放入缓存备用吗?显然不可以。例如下图 所示的事务操作中,SELECT 操作得到的查询结果中其实包含了前面 INSERT语句插入的信息。如果 SELECT查询结束后立刻将查询结果放入缓存,则在事务提交前缓存中就包含了事务中的信息,这是违背事务定义的。而如果之后该事务进行了回滚,则缓存中的数据就会和数据库中的数据不一致。
 因此,事务操作中产生的数据需要在事务提交时写入缓存,而在事务回滚时直接销毁。TransactionalCache装饰器就为缓存提供了这一功能。
它使用entriesToAddOnCommit属性将事务中产生的数据暂时保存起来,在事务提交时一并提交给缓存,而在事务回滚时直接销毁。
TransactionalCache类也支持将缓存的范围限制在事务以内,只要将clearOnCommit属性置为 true即可。这样,只要事务结束,就会直接将暂时保存的数据销毁掉,而不是写入缓存中。
因此,事务操作中产生的数据需要在事务提交时写入缓存,而在事务回滚时直接销毁。TransactionalCache装饰器就为缓存提供了这一功能。
它使用entriesToAddOnCommit属性将事务中产生的数据暂时保存起来,在事务提交时一并提交给缓存,而在事务回滚时直接销毁。
TransactionalCache类也支持将缓存的范围限制在事务以内,只要将clearOnCommit属性置为 true即可。这样,只要事务结束,就会直接将暂时保存的数据销毁掉,而不是写入缓存中。
# 14、MyBatis缓存机制
# 14.1、一级缓存
MyBatis 的一级缓存又叫本地缓存,其结构和使用都比较简单,与它相关的配置项有两个。
- 是在配置文件的 settings节点下,我们可以增加如下图所示的配置语句来改变一级缓存的作用范围。配置值的可选项有 SESSION与 STATEMENT,分别对应了一次会话和一条语句。一级缓存的默认作用范围是 SESSION

- 可以在映射文件的数据库操作节点内增加 flushCache属性项,如下图所示,该属性可以设置为 true或 false。当设置为 true时,MyBatis会在该数据库操作执行前清空一、二级缓存。该属性的默认值为 false

一级缓存源码实现:
一级缓存功能由 BaseExecutor类实现。
BaseExecutor类作为实际执行器的基类,为所有实际执行器提供一些通用的基本功能,在这里增加缓存也就意味着每个实际执行器都具有这一级缓存
在 BaseExecutor 内,可以看到与一级缓存相关的两个属性,分别是 localCache 和localOutputParameterCache,如下图所示。这两个属性使用的都是没有经过任何装饰器装饰的 PerpetualCache对象
 这两个变量中,localCache缓存的是数据库查询操作的结果。对于CALLABLE形式的语句,因为最终向上返回的是输出参数,便使用 localOutputParameterCache 直接缓存的输出参数。
因为 localCache 和 localOutputParameterCache 都是 Executor 的属性,不可能超出Executor 的作用范围。而 Executor 归属 SqlSession,因此第一级缓存的最大作用范围便是SqlSession,即一次会话。
这两个变量中,localCache缓存的是数据库查询操作的结果。对于CALLABLE形式的语句,因为最终向上返回的是输出参数,便使用 localOutputParameterCache 直接缓存的输出参数。
因为 localCache 和 localOutputParameterCache 都是 Executor 的属性,不可能超出Executor 的作用范围。而 Executor 归属 SqlSession,因此第一级缓存的最大作用范围便是SqlSession,即一次会话。
# 14.2、二级缓存
二级缓存的作用范围是一个命名空间(即一个映射文件),而且可以实现多个命名空间共享一个缓存。因此与一级缓存相比其作用范围更广,且选择更为灵活。 与二级缓存相关的配置项有四项
- 配置项在配置文件的 settings节点下,我们可以增加如下所示的配置语句来启用和关闭二级缓存。该配置项的默认值为 true,即默认启用二级缓存

- 第二个配置项在映射文件内。可以使用如下所示的 cache标签来开启并配置本命名空间的缓存,也可以使用如下 所示的标签来声明本命名空间使用其他命名空间的缓存,如果两项都不配置则表示命名空间没有缓存。该项配置只有在第一项配置中选择启用二级缓存时才有效


- 数据库操作节点内的 useCache属性,如下所示。通过它可以配置该数据库操作节点是否使用二级缓存。只有当第一、二项配置均启用了缓存时,该项配置才有效。对于 SELECT类型的语句而言,useCache属性的默认值为 true,对于其他类型的语句而言则没有意义

- 数据库操作节点内的 flushCache 属性项,该配置属性与一级缓存共用,表示是否要在该语句执行前清除一、二级缓存
二级缓存源码实现:
二级缓存功能由 CachingExecutor类实现,它是一个装饰器类,能通过装饰实际执行器为它们增加二级缓存功能。如下所示,在 Configuration的newExecutor方法中,MyBatis会根据配置文件中的二级缓存开关配置用CachingExecutor类装饰实际执行器

# 14.3、两级缓存机制
现在我们已经清楚 MyBatis 存在两级缓存,其中一级缓存由 BaseExecutor 通过两个PerpetualCache类型的属性提供,而二级缓存由 CachingExecutor包装类提供。
那么在数据库查询操作中,是先访问一级缓存还是先访问二级缓存呢?
答案并不复杂,CachingExecutor作为装饰器会先运行,然后才会调用实际执行器,这时 BaseExecutor 中的方法才会执行。因此,在数据库查询操作中,MyBatis 会先访问二级缓存再访问一级缓存

# 15、transaction包
负责进行事务管理的包,该包内包含两个子包: jdbc子包中包含基于 JDBC进行事务管理的类 managed子包中包含基于容器进行事务管理的类
整个transaction包使用工厂模式实现
 TransactionFactory 是所有事务工厂的接口
TransactionFactory 是所有事务工厂的接口
 Transaction 是所有事务的接口
Transaction 是所有事务的接口

# 15.1、jdbc事务
jdbc子包中存放的是实现 JDBC事务的 JdbcTransaction类及其对应的工厂类。 JdbcTransaction类是 JDBC事务的管理类 而具体的事务操作是由 JdbcTransaction类直接调用 Connection类提供的事务操作方法来完成的
# 15.2、容器事务
managed子包中存放的是实现容器事务的 ManagedTransaction类及其对应的工厂类。 在 ManagedTransaction类中,可以看到 commit、rollback等方法内都没有任何逻辑操作 那么这些方法是空的,又如何实现事务管理呢? 这是因为相关的事务操作都委托给了容器进行管理。以 Spring容器为例。当 MyBatis和 Spring集成时,MyBatis中拿到的数据库连接对象是 Spring给出的。Spring可以通过 XML配置、注解等多种方式来管理事务(即决定事务何时开启、回滚、提交)。 当然,这种情况下,事务的最终实现也是通过 Connection对象的相关方法进行的。 整个过程中,MyBatis 不需要处理任何事务操作,全都委托给 Spring即可
# 16、cursor包(游标)
使用场景: 在使用 MyBatis进行数据库查询时,经常会查询到大量的结果。在代码21-3所示的例子中,我们查询到了大量的 User对象,并使用 List接受这些对象
但有些时候,我们希望逐一读入和处理查询结果,而不是一次读入整个结果集。因为前者能够减少对内存的占用,这在处理大量的数据时会显得十分必要。 游标就能够帮助我们实现这一目的,它支持我们每次从结果集中取出一条结果。 在 MyBatis中使用游标进行查询非常简单,映射文件不需要任何的变动,只需要在映射接口中标明返回值类型是 Cursor即可


# 17、executor包
如果从 MyBatis的所有包中选择一个最为重要的包,那就是 executor包。 executor 包,顾名思义为执行器包,它作为 MyBatis 的核心将其他各个包凝聚在了一起。 在该包的工作中,会调用配置解析包解析出的配置信息,会依赖基础包中提供的基础功能。最终,executor包将所有的操作串接在了一起,通过 session包向外暴露出一套完整的服务。
# 17.1、主键自增
许多数据库都支持主键自增功能,如 MySQL数据库、SQL Server数据库等。当然也有一些数据库不支持主键自增功能,如 Oracle数据库。MyBatis的 executor包中的 keygen子包兼容以上这两种情况
 配置与生效:
配置与生效:
- 要启动Jdbc3KeyGenerator,可以配置文件中增加setting属性或者直接在相关语句中启用


- 要启用 SelectKeyGenerator,则需要在 SQL语句前加一段 selectKey标签

如果两个都配置了,则以后者(SelectKeyGenerator)为主
# 17.2、Jdbc3KeyGenerator类
Jdbc3KeyGenerator类是为具有主键自增功能的数据库准备的 既然数据库已经支持主键自增了,那 Jdbc3KeyGenerator类存在的意义是什么呢? 它存在的意义是提供自增主键的回写功能
# 17.3、SelectKeyGenerator类
可以真正地生成自增的主键 SelectKeyGenerator类实现了 processBefore和 processAfter这两个方法
# 17.4、懒加载
 aggressiveLazyLoading 是激进懒加载设置,我们对该属性进行一些说明。当aggressiveLazyLoading设置为 true时,对对象任一属性的读或写操作都会触发该对象所有懒加载属性的加载;当 aggressiveLazyLoading设置为 false时,对对象某一懒加载属性的读操作会触发该属性的加载。无论 aggressiveLazyLoading的设置如何,调用对象的“equals”“clone”“hashCode”“toString”中任意一个方法都会触发该对象所有懒加载属性的加载
aggressiveLazyLoading 是激进懒加载设置,我们对该属性进行一些说明。当aggressiveLazyLoading设置为 true时,对对象任一属性的读或写操作都会触发该对象所有懒加载属性的加载;当 aggressiveLazyLoading设置为 false时,对对象某一懒加载属性的读操作会触发该属性的加载。无论 aggressiveLazyLoading的设置如何,调用对象的“equals”“clone”“hashCode”“toString”中任意一个方法都会触发该对象所有懒加载属性的加载

 功能实现:
功能实现:

# 17.5、语句处理功能
在 MyBatis映射文件的编写中,我们常会见到“${}”和“#{}”这两种定义变量的符号,其含义如下
- ${}:使用这种符号的变量将会以字符串的形式直接插到 SQL片段中。
- #{}:使用这种符号的变量将会以预编译的形式赋值到 SQL片段中。
MyBatis中支持三种语句类型,不同语句类型支持的变量符号不同。MyBatis中的三种语句类型如下
- STATEMENT:这种语句类型中,只会对 SQL片段进行简单的字符串拼接。因此,只支持使用“${}”定义变量
- PREPARED:这种语句类型中,会先对 SQL片段进行字符串拼接,然后对 SQL片段进行赋值。因此,支持使用“${}”“#{}”这两种形式定义变量
- CALLABLE:这种语句类型用来实现执行过程的调用,会先对 SQL 片段进行字符串拼接,然后对 SQL片段进行赋值。因此,支持使用“${}”“#{}”这两种形式定义变量
在创建 SQL语句时,语句的类型由 statementType 属性进行指定。如果不指定则默认采用 PREPARED
在对CALLABLE语句进行调用时,可以直接使用Map来设置输入参数。使用MyBatis调用存储过程的操作如下图所示:


# 18、session包

# 18.1、DefaultSqlSession类
session包是整个 MyBatis应用的对外接口包,而 executor包是最为核心的执行器包。
DefaultSqlSession 类做的主要工作则非常简单——把接口包的工作交给执行器包处理

# 18.2、SqlSessionManager类

# 19、plugin包
# 二、源码结构展示
基础功能包:
- exceptions
- reflection
- annotations
- lang
- type
- io
- logging
- parsing
配置解析包:
- binding
- builder
- mapping
- scripting
- datasource
核心操作包:
- jdbc
- cache
- transaction
- cursor
- executor
- session
- plugin
# 三、源码包解析
# 1、reflection包(反射包)
# 1.1、factory包(工厂包)
public interface ObjectFactory {
default void setProperties(Properties properties) {
}
<T> T create(Class<T> type);
<T> T create(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs);
<T> boolean isCollection(Class<T> type);
}
2
3
4
5
6
7
8
9
10
11
12
13
DefaultObjectFactory为当前接口的默认实现
public class DefaultObjectFactory implements ObjectFactory, Serializable {
private static final long serialVersionUID = -8855120656740914948L;
@Override
public <T> T create(Class<T> type) {
return create(type, null, null);
}
@SuppressWarnings("unchecked")
@Override
public <T> T create(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
Class<?> classToCreate = resolveInterface(type);
// we know types are assignable
// 创建类型实例
return (T) instantiateClass(classToCreate, constructorArgTypes, constructorArgs);
}
/**
* 创建类的实例
* @param type 要创建实例的类
* @param constructorArgTypes 构造方法入参类型
* @param constructorArgs 构造方法入参
* @param <T> 实例类型
* @return 创建的实例
*/
private <T> T instantiateClass(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
try {
// 构造方法
Constructor<T> constructor;
if (constructorArgTypes == null || constructorArgs == null) { // 参数类型列表为null或者参数列表为null
// 因此获取无参构造函数
constructor = type.getDeclaredConstructor();
try {
// 使用无参构造函数创建对象
return constructor.newInstance();
} catch (IllegalAccessException e) {
// 如果发生异常,则修改构造函数的访问属性后再次尝试
if (Reflector.canControlMemberAccessible()) {
constructor.setAccessible(true);
return constructor.newInstance();
} else {
throw e;
}
}
}
// 根据入参类型查找对应的构造器
constructor = type.getDeclaredConstructor(constructorArgTypes.toArray(new Class[constructorArgTypes.size()]));
try {
// 采用有参构造函数创建实例
return constructor.newInstance(constructorArgs.toArray(new Object[constructorArgs.size()]));
} catch (IllegalAccessException e) {
if (Reflector.canControlMemberAccessible()) {
// 如果发生异常,则修改构造函数的访问属性后再次尝试
constructor.setAccessible(true);
return constructor.newInstance(constructorArgs.toArray(new Object[constructorArgs.size()]));
} else {
throw e;
}
}
} catch (Exception e) {
// 收集所有的参数类型
String argTypes = Optional.ofNullable(constructorArgTypes).orElseGet(Collections::emptyList)
.stream().map(Class::getSimpleName).collect(Collectors.joining(","));
// 收集所有的参数
String argValues = Optional.ofNullable(constructorArgs).orElseGet(Collections::emptyList)
.stream().map(String::valueOf).collect(Collectors.joining(","));
throw new ReflectionException("Error instantiating " + type + " with invalid types (" + argTypes + ") or values (" + argValues + "). Cause: " + e, e);
}
}
// 判断要创建的目标对象的类型,即如果传入的是接口则给出它的一种实现
protected Class<?> resolveInterface(Class<?> type) {
Class<?> classToCreate;
if (type == List.class || type == Collection.class || type == Iterable.class) {
classToCreate = ArrayList.class;
} else if (type == Map.class) {
classToCreate = HashMap.class;
} else if (type == SortedSet.class) { // issue #510 Collections Support
classToCreate = TreeSet.class;
} else if (type == Set.class) {
classToCreate = HashSet.class;
} else {
classToCreate = type;
}
return classToCreate;
}
@Override
public <T> boolean isCollection(Class<T> type) {
return Collection.class.isAssignableFrom(type);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
# 1.2、invoker包(执行器)
该子包中的类能够基于反射实现对象方法的调用和对象属性的读写
public interface Invoker {
// 方法执行调用器
Object invoke(Object target, Object[] args) throws IllegalAccessException, InvocationTargetException;
// 传入参数或者传出参数的类型(如有一个入参就是入参,否则是出参)
Class<?> getType();
}
2
3
4
5
6
三个默认实现: GetFieldInvoker:负责对象属性的读操作 SetFieldInvoker:负责对象属性的写操作 MethodInvoker:负责对象其它方法的操作
# 1.3、property包(属性)
该子包中的类用来完成与对象属性相关的操作
- PropertyCopier:属性拷贝器,可以方便的把一个对象的属性复制到另一个对象中
- copyBeanProperties方法的工作原理非常简单:通过反射获取类的所有属性,然后依次将这些属性值从源对象复制出来并赋给目标对象。但是要注意一点,该属性复制器无法完成继承得来的属性的复制,因为 getDeclaredFields方法返回的属性中不包含继承属性
- PropertyNamer:属性(包括属性方法)名称处理器
- PropertyTokenizer:是一个属性标记器。传入一个形如“student[sId].name”的字符串后,该标记器会将其拆分开,放入各个属性中
# 1.4、wrapper包(对象包装器)
使用装饰器模式对各种类型的对象进行进一步的封装,为其增加一些功能,使之更易于使用
- ObjectWrapperFactory:是对象包装器工厂的接口,DefaultObjectWrapperFactory是默认实现,该默认节点没有实现任何功能,Mybatis也允许用户通过配置文件中的objcetWrapperFactory节点,来注入新的ObjectWrapperFactory
- ObjectWrapper:是所有对象包装器的总接口
- BeanWrapper:包含了一个Bean的对象信息、类型信息、并提供了更多的功能,一个bean通过BeanWrapper包装后就可以暴露大量的易用方法,可以简单的实现对其方法、属性的操作 get:获得被包装对象某个属性的值 set:设置被包装对象某个属性的值 findProperty:找到对应的属性值 getGetterNames:获取所有属性的get方法名称 getSetterNames:获得所有属性的set方法名称 getGetterType:获取指定属性的get方法的类型 getSetterType:获取指定属性的set方法的类型 hasGetter:判断某个属性是否有对应的get方法 hasSetter:判断某个属性是否有对应的set方法 instantiatePropertyValue:实例化某个属性的值
- MapWrapper:对于Map类型的包装
- CollectionWrapper:对于集合类型的封装
# 1.5、reflector(反射核心类)
负责对一个类进行反射解析,并将解析后的结果储存起来,解析一个类的过程是用构造函数触发的,逻辑非常清晰
# 1.6、ExceptionUtil(异常拆包工具)
提供了一个拆包异常的工具方法unwrapThrowable,该方法将InvocationTargeException和UndeclaredThrowableException这两类异常进行拆包,得到其中真正的异常
# 1.7、ParamNameResolver(参数名解析器)
功能是按照顺序列出方法中的虚参,并对实参进行名称标注 主要涉及的是对字符串的处理
# 1.8、TypeParameterResolver(泛型参数解析器)
功能是帮助Mybatis推断出属性、返回值、输入参数中的泛型的具体类型 比如List\<\T> 中的这个T具体是什么类型,User? Map?等
对外提供了三个方法
- resolverFieldType 解析属性的泛型
- resolverReturnType 解析方法返回值的泛型
- resolverParamTypes 解析方法输入参数的泛型
核心方法resolverType
/**
* 解析变量的实际类型
* @param type 变量的类型
* @param srcType 变量所属于的类
* @param declaringClass 定义变量的类
* @return 解析结果
*/
private static Type resolveType(Type type, Type srcType, Class<?> declaringClass) {
if (type instanceof TypeVariable) { // 如果是类型变量,例如“Map<K,V>”中的“K”、“V”就是类型变量。
return resolveTypeVar((TypeVariable<?>) type, srcType, declaringClass);
} else if (type instanceof ParameterizedType) { // 如果是参数化类型,例如“Collection<String>”就是参数化的类型。
return resolveParameterizedType((ParameterizedType) type, srcType, declaringClass);
} else if (type instanceof GenericArrayType) { // 如果是包含ParameterizedType或者TypeVariable元素的列表
return resolveGenericArrayType((GenericArrayType) type, srcType, declaringClass);
} else {
return type;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 2、annotations包(注解包)
java注解是一种标注。 java中的类、方法、变量、参数、包等都可以被注解标注从而添加额外的信息
# 2.1、元注解
- @Target:用来声明注解可以用在什么地方,值需要在枚举中获取,包括:
- TYPE(类、接口、注解、枚举)
- FIELD(字段)
- METHOD(方法)
- PARAMETER(参数)
- CONSTRUCTOR(构造方法)
- LOCAL_VARIABLE(本地变量)
- ANNOTATION_TYPE(注解)
- PACKAGE(包)
- TYPE_PARAMTER(类型参数)
- TYPE_USE(类型使用)
- @Retention:用来声明注解的声明周期
- SOURCE:保留到源代码阶段,一般给编译器使用
- CLASS:保留到类文件阶段,这是默认的生命周期,JVM运行时不包含这些信息
- RUNTIME:保留到JVM运行时期
- @Documented:不需要设置具体的值,如果一个注解被Documented标注,则该注解会在javadoc中生成
- @Inherited:不需要设置具体的值,标识子类可以继承父类的该注解(只能继承,不能从接口继承)
- @Repeatable:表名该注解可以在同一个地方被重复使用
# 2.2、Param注解
依赖开发工具可以找到Mybatis对于Param注解的解析是在ParamNameResolver构造方法中
# 3、type包
type包中的类有55个之多,在遇到这种繁杂的情况时,一定要注意归纳总结 归纳总结是阅读源码中非常好的方法
type包中的类可以分为6组
- 类型处理器:1个接口、1个基础实现类、1个辅助类、43个实现类
- TypeHandler:类型处理器接口
- BaseTypeHandlerr:类型处理器的基础实现
- TypeReference:类型参考器
- **TypeHandler:43个类型处理器
- 类型注册表:3个
- SimpleTypeRegistry:基本类型注册表,内部使用Set维护了所有Java基本数据类型的集合
- TypeAliasRegistry:类型别名注册表,内部使用HashMap为了所有类型的别名和类型的映射关系
- TypeHandleRegistry:类型处理器注册表,内部维护了所有类型与对应类型处理器的映射关系
- 注解类:3个
- Alias:使用该注解可以给类设置别名
- MappedJdbcTypes:有时我们想使用自己的处理器来处理某些JDBC类型,只需创建BaseTypeHandler的子类,然后在上面加上该注解,声明它要处理的JDBC类型即可
- MappedTypes:有时我们想使用自己的处理器来处理某些java类型,只需要创建BaseTypeHandler的子类,然后在上面增加该注解,声明它要处理的Java类型即可
- 异常类:1个
- TypeException:表示与类型处理相关的异常
- 工具类:1个
- ByteArrayUtils:提供数组转化的工具方法
- 枚举类:1个
- JdbcType:在Enum中定义了所有的JDBC类型,类型来源于java.sql.Types
# 4、io包
完成mybatis中输入输出相关的操作
# 4.1、vfs
磁盘文件有很多种,FAT、VFAT、NFS、NTFS等,不同文件系统的读写操作各不相同,VFS作为一个虚拟的文件系统,可以屏蔽底层的操作差异,提供统一的操作接口 vfs的作用是在应用系统中寻找和读取资源文件
vfs包中相关的类主要是3个
DefaultVFS:
作为默认的VFS实现,isVaild函数恒返回true,因此只要加载DefauktVFS类,就一定能够通过VFS类中的VFSHolder单例中的校验,并且在进行类校验时,DefaultVFS在整个列表的最后,所以可以作为兜底方案
- list(URL,String):列出指定URL下符合条件的资源名称
- listResources(JarInputStream,String):列出给定jar包中符合条件的资源名称
- findJarForResource(URL):找出指定路径上的jar包,并返回jar包的准确路径
- getPackagePath(String):将jar包名称转为路径
- isJar:判断指定路径上是否是jar包
JBoss6VFS:
JBoss是基于J2EE的开源应用服务器
# 4.2、classLoaderWrapper(类加载)
要把文件加载成类,需要类加载器的支持 classLoaderWrapper内部封装了5种类加载器,这5中类加载器优先级由高到低,在读取类文件时,依次在5种类加载器中进行查找,查找到即返回结果
- 作为参数传入的类加载器,可能为null
- 系统默认的类加载器,未设置则为null
- 当前线程的线程上下文的类加载器
- 当前对象的类加载器
- 系统类加载器,在ClassLoaderWrapper构造方法中设置
classForName()
根据类名找出指定类的方法
# 4.3、ResolverUtil(工具类)
主要完成类的筛选,筛选条件可以是: 1、类是否是某个接口或者类的子类 2、类是否具有某个注解
# 5、logging(日志包)
# 5.1、日志等级:
- Fatal:致命等级的日志,发生了会导致应用程序退出的事件
- Error:错误等级的日志,发生了错误,但是不影响应用运行
- Warn:警告等级的日志,发生了异常,可能是潜在的错误
- Info:信息等级的日志,在一些粗粒度级别上需要强调的应用程序运行信息
- Debug:调试等级的日志,指一些细粒度的对于程序调试有帮助的信息
- Trace:跟踪等级的日志,指一些程序运行详细过程的信息
# 5.2、LogFactory
LogFactory生成目标对象的工作在静态代码块中被触发
# 5.3、jdbc
jdbc日志包存在的意义? Mybatis是ORM框架,负责数据库信息和java对象的互相映射,而不负责具体的数据库读写操作,具体的读写操作由JDBC完成,所以Mybatis的日志便不会包含JDBC的操作日志 但是有时候很多错误是JDBC导致的,因此JDBC日志是分析Mybatis框架报错的重要依据 JDBC日志有自己的输出体系,会给调试工作带来困难,所以jdbc子包就是为了解决这个问题
BaseJdbcLogger的各个子类使用动态代理来实现日志的打印,比如ConnectionLogger
1、实现jdk动态代理
2、BaseExecutor入口处调用ConnectionLogger生成代理对象
3、执行invoker方法,进行日志打印
# 6、parsing包(XML解析)
mybatis的配置文件和映射文件都是XML 在解析过程中,XPathParser 和 XNode是两个最为关键的类 XPathParser内部封装了XPath对象,XPath是解析XML的利器
# 6.1、GenericTokenParser
通用的占位符解析器,比如sql中的{} # $都是这个解析器进行解析替换 类中唯一一个parse方法,该方法主要完成占位符的定位工作,然后把占位符的替换工作交给与其关联的TokenHandler处理,
例如传入的参数是 openToken:"${" closeToken:"}" 向GenericTokenParser的parse方法传入的参数是"jdbc:mysql://127.0.0.1:3306/${dbname}" 则parse方法会将被"${" 和 "}"包围的dbname字符串解析出来,作为输入参数传入handler中的handleToken方法,然后用返回值替换${dbname}字符串
# 7、binding包(绑定关系)
主要用来处理java方法与SQL语句之间绑定关系的包 binding包维护了映射接口中方法和数据库操作节点之间的关联关系 1、维护映射接口中的抽象方法与数据库操作节点之间的关联关系 2、为映射接口中的抽象方法接入对应的数据库操作
# 7.1、数据库的接入
要想将一个数据库接入一个抽象方法中,首先要做的就是将一个数据库节点操作转化为一个方法,MapperMethod对象就表示数据库操作转化后的方法,每个MapperMethod对象都对应一个数据库操作节点,调用实例中的execute就可以触发节点中的SQL语句
MapperMethod:有两个属性(两个重要的内部类)
MethodSignature 方法签名(持有这个方法的详细信息)
SqlCommand sql语句(持有这个方法对应的SQL语句)
SqlCommand构造方法主要通过传入的参数完成name和type的赋值,其中的resolveMappedStatement子方法是一切的关键。
只要调用MapperMethod的execute就可以触发具体的数据库操作
# 7.2、数据库操作方法的接入
如何调用execute方法? 当调用映射接口中的方法时,java会去找接口 的实现类并执行该方法,但是映射接口是没有实现类的,为什么没有报错,而是去执行了MapperMethod的execute方法呢 答案就是动态代理MapperProxy
# 7.3、抽象方法与数据库操作节点的关联
映射接口文件(xxxMapper.class)这么多,内置的抽象方法也很多,另一方面,映射文件(xxxMapper.xml)也很多,一切的对应关系怎么去维护呢?
Mybatis分两步解决了这个问题:
1、Mybatis将映射接口与MapperProxyFactory关联起来,这种关联关系是在MapperRegistry类的knownMappers属性中维护的
MapperProxyFactory的构造方法只有一个参数,便是映射接口,并且其余属性不允许修改,所以只要MapperProxyFactory对象确定了,MapperProxy也就确定了,于是,MapperRegistry中的knownMappers属性间接的将映射接口与MapperProxy对象关联起来
2、此时的范围已经缩小到一个映射接口或者一个MapperProxy对象内,由MapperProxy内部的methodCache属性维护接口方法和MapperMethod对象的对应关系
通过这两步,生成的对应关系就如图所示
# 7.4、数据库操作接入总结
# 7.4.1、初始化阶段:
Mybatis在初始化阶段会进行各个映射文件的解析,然后将各个数据库操作节点的信息记录到Configuration对象的mappedStatements中(结构是一个StrictMap表示一个不允许覆盖键值的HashMap) 在初始化阶段,扫描所有的映射接口,并根据映射接口创建与之关联的MapperProxyFactory,两者的关联关系由MapperResigtry维护,当调用MapperRegistry的getMapper方法,就会通过MapperProxyFactory创建一个MapperProxy对象作为映射接口的代理
# 7.4.2、数据读写阶段
当映射接口有方法被调用时,会被代理对象MapperProxy劫持,触发MapperProxy内部的invoker方法,invoker方法会取出映射接口对应的MapperMethod对象 创建MapperMethod对象过程中,内部类SqlCommand的构造方法会去Configuratio对象的mappedStatements属性中根据当前映射接口名、方法名获取到前期已经存好的SQL语句 然后MapperMethod的execute方法被触发,方法内部会根据不同的SQL语句类型进行不同的数据库操作
# 8、builder包
# 8.1、建造者基类和工具类
BaseBuilder是所有建造者的基类
BaseBuilder类提供的工具方法大致分为以下几类:
- **ValueOf:类型转化函数,负责将输入参数转化为指定的类型,并支持默认值设置
- resolve**:字符串转枚举类型函数,根据字符串找出对应的枚举类型并返回
- createInstance:根据类型别名创建类型实例
- resolverTypeHandle:根据类型处理器别名返回类型处理器实例
# 8.2、SqlSourceBuilder、StaticSqlSource
SqlSource是一个接口,有4种实现,通过parse方法生产出StaticSqlSource对象
准确的说,SqlSourceBuilder能够将DynamicSqlSource和RawSqlSource中的#$替换掉,从而将它们转化为StaticSqlSource
StaticSqlSource中的Sql语句已经不包含#{} ${},而是?,还有一个重要功能就是给出一个BoundSql对象
# 8.3、CacheRefResolver
mybatis支持多个namespace之间共享缓存,使用cache-ref标签,可以声明另一个namespace 如下所示,代表的含义是UserDao可以使用TaskDao的缓存
CacheRefResolver就是用来处理多个命名空间共享缓存的问题
# 8.4、ResultMapResolver
mybatis的resultMap标签允许继承,通过extends=xxxMap继承xxxMap设置的属性映射
ResultMapResolver就是用来解析resultMap的继承关系
# 8.5、ParameterExpression(属性解析器)
用来将描述属性的字符串解析为键值对的形式
# 8.6、xml
xml包中一共有5个解析器,负责将xml文件解析成对应的类,每个类解析的范围如下图
- XMLMapperEntityResolver
- XMLConfigBuilder
- XMLMapperBuilder
- XMLStatementBuilder
- XMLIncludeTransformer
# 8.6.1、xml文件声明的解析
XML文件可以引用外部的DTD文件对XML文件进行校验,但是Mybatis有可能运行在无网络的环境中,无法联网下载DTD文件,针对于这种情况 XMLMapperEntityResolver就是解决这种问题的,在方法resolveEntity通过字符串匹配本地的DTD文件并返回
# 8.6.2、配置文件的解析
配置文件的解析是由XMLConfigBuilder负责的,同时解析之后构建出一个Configuration对象
# 8.6.3、数据库操作语句解析
映射文件的解析由XMLMapperBuilder负责
Q&A:
Q:解析过程中遇见循环依赖问题,Mybatis怎么解决的?比如解析xxxMapper中出现了extends属性,但是继承的属性还没有被解析,怎么办?
A:有两种解决方案
1、第一次全部解析,遇到错误先标记然后跳过,第二次只处理错误(Mybatis)
2、第一次解析只读如所有节点,但不处理依赖关系,然后在第二轮解析时只处理依赖关系(Spring)
Mybatis使用的第一种方式,Configuration中有一些属性转门记录临时性错误节点,在第二次解析时取出对应的属性值进行解析
# 8.6.4、Statement解析
数据库操作节点(select、update、delete、insert)由XMLStatementBuilder完成
# 8.6.5、引用解析
对于\<\include refid="">节点的解析是XMLIncludeTransformer负责的,能够将标签中的include节点替换为被引用的SQL片段
# 8.6.6、注解映射的解析
builder包中的annotation包就是用来解析注解配置映射
开发过程中可以在映射接口中的抽象方法增加注解的方式来声明数据库操作
# 9、mapping包(解析实体类)
mapping包主要完成了下列功能:
- SQL语句处理功能
- 输出结果处理功能
- 输入参数处理功能
- 多数据库种类处理功能
- 其他功能
# 9.1、SQL语句处理功能
MappeddStatement:数据库操作节点(select、insert、)的所有内容
SqlSource:数据库操作标签包含的SQL语句
BoundSql:对于SqlSource的进一步处理
# 9.2、输出结果处理功能
Mybatis在映射文件的数据库操作节点中,可以使用ResultType把结果直接转换为java对象,另外一种更灵活的方式是使用ResultMap来定义输出结果的映射方式
ResultMap的功能十分强大,支持输出结果的组装、判断、懒加载,例如下面的代码例子就是根据sex的不同输出不同的子类
ResultMap标签的解析关系
# 9.3、输入参数处理功能
可以将对象映射成SQL语句需要的输入参数,使用parameterMap
代码示例:
# 9.4、多数据库种类处理功能
mybatis支持多种数据库,需要在配置文件中先列举需要使用的数据库类型
配置文件设置数据库:
然后在SQL语句对应数据库类型
实现原理:
多数据支持的实现由DatabaseIdProvider接口负责,有一个子类VendorDatabaseIdProvider,主要方法是setProperties和getDatabaseId
setProperties方法:将Mybatis配置文件中设置在databeseIdProvider节点中的信息写入VendorDatabaseIdProvider对象中
getDataBaseId方法:给出当前传入的datasource对象对应的databaseId,主要逻辑在getDatabaseName方法中
# 10、scripting包
SQL脚本中可以编写if、foreach、where等条件标签,这些标签的解析主要由scripting包完成的
# 10.1、OGNL
是一种功能强大的表达式语言,通过它,能够完成从集合中选取对象、读写对象的属性、调用对象和类的方法、表达式求值和判断等操作 OGNL有java工具包,只要引入就可以在java中使用OGNL功能
OGNL的三个重要概念:
- 表达式(expression):是一个带语法含义的字符串,是整个OGNL的核心内容,通过表达式来确定需要进行的OGNL操作
- 根对象(root):可以理解为OGNL的被操作对象,表达式中的操作就是针对这个对象展开的
- 上下文(context):整个OGNL处理的上下文环境,是一个Map对象
# 10.2、languageDriver
语言驱动类的接口,有两个默认实现,XMLLanguageDriver和RawLanguageDriver
# 10.3、XMLScriptBuilder
映射文件中的语句有很多sql标签组成的一棵树,要想解析这颗树,首先需要将xml内容读取出来,然后在内存中构建SQL节点树,SQL节点树的构建由XMLScriptBuilder完成。
内部含有接口NodeHandle,每个SQL节点都有一个NodeHandle的实现,SQL节点和对应的Handle实现类的对应关系由nodeHandleMap维护

mybatis并没有把OGNL直接暴露给各个SQL节点使用,而是对OGNL进行更易用性的封装,对外暴露了ExpressionEvaluator类(表达式求值器)
提供了两个方法
- evaluateBoolean:能够对true或者false形式的表达式求值,例如if节点
- evaluateIterable:能够对结果是迭代形式的表达式进行求值,例如foreach
# 10.6、DynamicContext(动态上下文)
一方面,在进行SQL树的解析时,需要不断的保存已经解析完成的SQL片段; 另一方面,在进行SQL节点树的解析时,也需要一些参数和环境信息,作为解析的依据 以上的两个功能就是由动态上下文来提供的
根据构造方法可以清楚的看出上下文环境是如何被创建出来的:
上下文的bindings中存储了如下信息:
- 数据库id,因此在编写SQL语句时,我们可以直接使用DATABASE_ID_KEY引用数据库id的值
- 参数对象,在编写SQL语句时,可以直接使用PARAMETER_OBJECT_KEY变量来引用整个参数对象
- 参数对象的元数据,基于参数对象的元数据可以方便的引用参数对象的属性值,因此在编写SQL语句时可以直接引用参数对象的属性
# 10.7、SqlNode
SqlNode是一个接口,其中只定义了一个apply方法,该方法负责完成自身节点的解析,并将解析结果合并到输入参数提供的上下文环境中 编写的if where这些标签对应的就是一个SqlNode,分别对应IfSqlNode和WhereSqlNode
# 11、datasource包(数据源)
# 11.1、DataSourceFactory数据源工厂接口
mybatis是根据datasource的type属性进行工厂的选择
# 11.2、JndiDataSourceFactory
JNDI(Java Naming and Directory Interface)java命名和目录接口 能够为java程序提供命名和目录访问的接口,可以理解为一个命名规范,在使用该规范为资源命名并放入环境(context)中,我们可以根据名称从环境中查找(lookup)对应的资源 JndiDataSourceFactory的作用就是从环境中找出指定的 JNDI数据源
在mybatis中使用JNDI:
- initial_context:起始环境信息,Mybatis会在这里寻找指定的数据源,如果不设置,Mybatis会在整个环境中寻找数据源
- data_source:数据源名称
# 11.3、UnpooledDataSourceFactory
非池化数据源工厂,需要真正的创建一个数据源,不过创建过程很简单,直接在构造方法中创建数据源对象,并保存在自身的成员变量中,
非池化数据源是最简单的数据源,只需要在每次请求连接时打开连接,在每次连接结束时断开连接
在Mybatis中使用UNPOOLED来代表非池化数据源
# 11.4、PooledDataSourceFactory
池化数据源,在连接池中总保留一定数量的数据库连接以备使用,可以在需要时取出,用完后放回,减少连接的创建和销毁工作,提升整体的效率
PooledDataSource:
- state:是一个PoolSate对象,存储了所有的数据库连接和状态信息,在类属性中,使用idleConnections和activeConnections两个列表存储了所有的空余连接和活跃连接,除此之外,还有大量的属性来存储连接池运行过程中的统计信息
- dataSource:当池化的数据源在连接池中的连接不够时,也需要创建新的连接,dataSource属性是一个UnPooledDataSource对象
- expectedConnectionTypeCode:一个数据源连接池必须确保池中的每个连接都是等价的,这样才能确保我们每次从连接池中取出连接不会存在差异。该属性存储的该数据源连接类型编码
# 11.5、池化连接的给出和收回
- 给出池化连接:方法是popConnection,方法的伪代码总结如下图
- 收回池化连接,方法pushConnection
# 11.6、PooledConnection
池化连接,当我们要关闭一个池化连接时,它不应该真正的被关掉,而是应该将自己放回连接池,所以,通过PooledDataSource获取的数据库连接,不能是普通的Connection对象
pooled子包中存在一个PooledConnection对象,是对普通Connection对象的代理,其中一个重要工作就是修改Connection类的close方法的行为
# 12、jdbc包
该包提供了数据库操作语句的能力和脚本运行能力
# 12.1、AbstractSQL
抽象类,含有一个抽象方法getSelf 包含两个静态内部类SafeAppendable 、 SQLStatement
SafeAppendable: 是一个拼接器,append方法能实现串的拼接功能 SQLStatement: 可以完整的表述出一条SQL语句
# 12.2、SqlRunner
可以直接执行SQL语句的工具类 SqlRunner可以接受SQL语句和参数,然后执行数据库操作,不过并不能完成对象和SQL参数、结果等的对象映射
# 12.3、ScriptRunner
可以直接执行脚本的工具类,开发者可以直接把整个脚本文件交给Mybatis执行
# 13、cache包
cache包是典型的装饰器模式的应用案例,在imple子包存放了实现类,在decorators子包中存放了众多装饰器类,而cache接口是实现类和装饰器类的共同接口
# 13.1、CacheKey缓存键
Mybatis每秒过滤众多的数据库查询操作,这对Mybatis缓存键的设计提出了很高的要求,必须满足一下几点
- 无碰撞:必须保证两个不同的查询请求生成的键不一致,
- 高效比较:每次缓存查询操作都可能会引发键之间的多次比较,因此该操作必须是高效的
- 高效生成:每次缓存查询和写入操作都需要生成缓存的键,因此该操作也必须是高效的
缓存键的生成:
在数据库查询时,会根据当前的查询条件生成一个CacheKey,在BaseExecutor中可以看到这个过程
# 13.2、PerpetualCache
缓存的实现类,只有两个属性 id:用来标识一个缓存,一般使用映射文件的namespace作为缓存的id,这样能保证不同的映射文件的缓存是不同的 cache:是一个hashMap,采用键值对的形式来存储数据
# 13.3、缓存装饰器
decorators包下存在很多的装饰器,根据装饰器的功能可以将他们分为几个大类
- 同步装饰器:为缓存增加同步功能 如SynchronizedCache
- 日志装饰器:为缓存增加日志功能 如LoggingCache
- 清理装饰器:为缓存中的数据增加清理功能,如FifoCache,LruCache
- 阻塞装饰器:为缓存增加阻塞功能,如BlockingCache
- 定时清理装饰器:为缓存增加定时刷新功能,如ScheduledCache
- 序列化装饰器:为缓存增加序列化功能,如SerializedCache
- 事务装饰器:用于支持事务操作的装饰器,如TransactionCache
# 13.3.1、同步装饰器
在Mybatis使用过程中,可能会出现多个线程同时访问一个缓存的情况,例如下图代码所示,如果多个线程同时调用selectUsers方法,而缓存实现类PerpetualCache并没有增加任何多线程的保护措施,会引发线程安全问题,而Mybatis将这项工作交给了SynchronizedCache,它的实现非常简单,在被包装的对象方法外围增加Synchronized关键字,使得方法编程同步方法
# 13.3.2、日志装饰器
为数据库操作增加缓存的目的是减少数据库的查询操作从而提高运行效率。而缓存的配置也非常重要,如果配置过大则浪费内存空间,如果配置过小则无法更好地发挥作用。因此,需要依据一些运行指标来设置合适的缓存大小。
日志装饰器可以为缓存增加日志统计的功能,而需要统计的数据主要是缓存命中率。所谓缓存命中率是指在多次访问缓存的过程中,能够在缓存中查询到数据的比率。
日志装饰器的实现非常简单,即在缓存查询时记录查询的总次数与命中次数
# 13.3.3、清理装饰器
虽然缓存能够极大地提升数据查询的效率,但这是以消耗内存空间为代价的。 缓存空间总是有限的,因此为缓存增加合适的清理策略以最大化地利用这些缓存空间十分重要。 缓存装饰器中有四种清理装饰器可以完成缓存清理功能,这四种清理装饰器也对应了MyBatis的四种缓存清理策略
- FifoCache装饰器:采用先进先出的策略来清理缓存,它内部使用了 keyList属性存储了缓存数据的写入顺序,并且使用 size属性存储了缓存数据的数量限制。当缓存中的数据达到限制时,FifoCache装饰器会将最先放入缓存中的数据删除
- LruCache装饰器:即近期最少使用算法,该算法会在缓存数据数量达到设置的上限时将近期未使用的数据删除。LruCache 装饰器便可以为缓存增加这些功能
- WeakCache装饰器:通过将缓存数据包装成弱引用的数据,从而使得 JVM可以清理掉缓存数据
- SoftCache装饰器:SoftCache 装饰器和 WeakCache 装饰器在结构、功能上高度一致,只是从弱引用变成了软引用
# 13.3.4、阻塞装饰器
当 MyBatis 接收到一条数据库查询请求,而对应的查询结果在缓存中不存在时,MyBatis会通过数据库进行查询。试想如果在数据库查询尚未结束时,MyBatis又收到一条完全相同的数据库查询请求,那应该怎样处理呢?常见的有以下两种方案。
- 因为缓存中没有对应的缓存结果,因此再发起一条数据库查询请求,这会导致数据库短时间内收到两条完全相同的查询请求。·
- 虽然缓存中没有对应的缓存结果,但是已经向数据库发起过一次请求,因此缓存应该先阻塞住第二次查询请求。等待数据库查询结束后,将数据库的查询结果返回给两次查询请求即可。
显然,后一种方案更为合理。阻塞装饰器 BlockingCache 为缓存提供了上述功能
# 13.3.5、定时清理装饰器
当调用缓存的 clear方法时,会清理缓存中的数据。但是该操作不会自动执行。 定时清理装饰器 ScheduledCache则可以按照一定的时间间隔来清理缓存中的数据,即按照一定的时间间隔调用 clear方法
# 13.3.6、序列化装饰器
有些场景下,我们不想让外部的引用污染缓存中的对象。这时必须保证外部读取缓存中的对象时,每次读取的都是一个全新的拷贝而不是引用。 序列化装饰器SerializedCache为缓存增加了这一功能。在使用 SerializedCache后,每次向缓存中写入对象时,实际写入的是对象的序列化串;而每次读取对象时,会将序列化串反序列化后再返回。 通过序列化和反序列化的过程保证了每一次缓存给出的对象都是一个全新的对象,对该对象的修改不会影响缓存中的对象。 当然,这要求被缓存的数据必须是可序列化的,否则SerializedCache会抛出异常
# 13.4、缓存的组建
组建缓存的过程就是根据需求为缓存的基本实现增加各种装饰的过程,该过程在CacheBuilder中完成
在映射文件中,我们可以通过如下所示的片段指定缓存的特性
# 13.5、事务缓存
在数据库操作中,如果没有显式地声明事务,则一条语句本身就是一个事务。在查询语句进行数据库查询操作之后,相应的查询结果可以立刻放入缓存中备用。
那么,事务中的语句进行数据库查询操作之后,相应的查询结果可以立刻放入缓存备用吗?显然不可以。例如下图 所示的事务操作中,SELECT 操作得到的查询结果中其实包含了前面 INSERT语句插入的信息。如果 SELECT查询结束后立刻将查询结果放入缓存,则在事务提交前缓存中就包含了事务中的信息,这是违背事务定义的。而如果之后该事务进行了回滚,则缓存中的数据就会和数据库中的数据不一致。
因此,事务操作中产生的数据需要在事务提交时写入缓存,而在事务回滚时直接销毁。TransactionalCache装饰器就为缓存提供了这一功能。
它使用entriesToAddOnCommit属性将事务中产生的数据暂时保存起来,在事务提交时一并提交给缓存,而在事务回滚时直接销毁。
TransactionalCache类也支持将缓存的范围限制在事务以内,只要将clearOnCommit属性置为 true即可。这样,只要事务结束,就会直接将暂时保存的数据销毁掉,而不是写入缓存中。
# 14、MyBatis缓存机制
# 14.1、一级缓存
MyBatis 的一级缓存又叫本地缓存,其结构和使用都比较简单,与它相关的配置项有两个。
- 是在配置文件的 settings节点下,我们可以增加如下图所示的配置语句来改变一级缓存的作用范围。配置值的可选项有 SESSION与 STATEMENT,分别对应了一次会话和一条语句。一级缓存的默认作用范围是 SESSION
- 可以在映射文件的数据库操作节点内增加 flushCache属性项,如下图所示,该属性可以设置为 true或 false。当设置为 true时,MyBatis会在该数据库操作执行前清空一、二级缓存。该属性的默认值为 false
一级缓存源码实现:
一级缓存功能由 BaseExecutor类实现。
BaseExecutor类作为实际执行器的基类,为所有实际执行器提供一些通用的基本功能,在这里增加缓存也就意味着每个实际执行器都具有这一级缓存
在 BaseExecutor 内,可以看到与一级缓存相关的两个属性,分别是 localCache 和localOutputParameterCache,如下图所示。这两个属性使用的都是没有经过任何装饰器装饰的 PerpetualCache对象
这两个变量中,localCache缓存的是数据库查询操作的结果。对于CALLABLE形式的语句,因为最终向上返回的是输出参数,便使用 localOutputParameterCache 直接缓存的输出参数。
因为 localCache 和 localOutputParameterCache 都是 Executor 的属性,不可能超出Executor 的作用范围。而 Executor 归属 SqlSession,因此第一级缓存的最大作用范围便是SqlSession,即一次会话。
# 14.2、二级缓存
二级缓存的作用范围是一个命名空间(即一个映射文件),而且可以实现多个命名空间共享一个缓存。因此与一级缓存相比其作用范围更广,且选择更为灵活。 与二级缓存相关的配置项有四项
- 配置项在配置文件的 settings节点下,我们可以增加如下所示的配置语句来启用和关闭二级缓存。该配置项的默认值为 true,即默认启用二级缓存
- 第二个配置项在映射文件内。可以使用如下所示的 cache标签来开启并配置本命名空间的缓存,也可以使用如下 所示的标签来声明本命名空间使用其他命名空间的缓存,如果两项都不配置则表示命名空间没有缓存。该项配置只有在第一项配置中选择启用二级缓存时才有效
- 数据库操作节点内的 useCache属性,如下所示。通过它可以配置该数据库操作节点是否使用二级缓存。只有当第一、二项配置均启用了缓存时,该项配置才有效。对于 SELECT类型的语句而言,useCache属性的默认值为 true,对于其他类型的语句而言则没有意义
- 数据库操作节点内的 flushCache 属性项,该配置属性与一级缓存共用,表示是否要在该语句执行前清除一、二级缓存
二级缓存源码实现:
二级缓存功能由 CachingExecutor类实现,它是一个装饰器类,能通过装饰实际执行器为它们增加二级缓存功能。如下所示,在 Configuration的newExecutor方法中,MyBatis会根据配置文件中的二级缓存开关配置用CachingExecutor类装饰实际执行器
# 14.3、两级缓存机制
现在我们已经清楚 MyBatis 存在两级缓存,其中一级缓存由 BaseExecutor 通过两个PerpetualCache类型的属性提供,而二级缓存由 CachingExecutor包装类提供。
那么在数据库查询操作中,是先访问一级缓存还是先访问二级缓存呢?
答案并不复杂,CachingExecutor作为装饰器会先运行,然后才会调用实际执行器,这时 BaseExecutor 中的方法才会执行。因此,在数据库查询操作中,MyBatis 会先访问二级缓存再访问一级缓存
# 15、transaction包
负责进行事务管理的包,该包内包含两个子包: jdbc子包中包含基于 JDBC进行事务管理的类 managed子包中包含基于容器进行事务管理的类
整个transaction包使用工厂模式实现
TransactionFactory 是所有事务工厂的接口
Transaction 是所有事务的接口
# 15.1、jdbc事务
jdbc子包中存放的是实现 JDBC事务的 JdbcTransaction类及其对应的工厂类。 JdbcTransaction类是 JDBC事务的管理类 而具体的事务操作是由 JdbcTransaction类直接调用 Connection类提供的事务操作方法来完成的
# 15.2、容器事务
managed子包中存放的是实现容器事务的 ManagedTransaction类及其对应的工厂类。 在 ManagedTransaction类中,可以看到 commit、rollback等方法内都没有任何逻辑操作 那么这些方法是空的,又如何实现事务管理呢? 这是因为相关的事务操作都委托给了容器进行管理。以 Spring容器为例。当 MyBatis和 Spring集成时,MyBatis中拿到的数据库连接对象是 Spring给出的。Spring可以通过 XML配置、注解等多种方式来管理事务(即决定事务何时开启、回滚、提交)。 当然,这种情况下,事务的最终实现也是通过 Connection对象的相关方法进行的。 整个过程中,MyBatis 不需要处理任何事务操作,全都委托给 Spring即可
# 16、cursor包(游标)
使用场景: 在使用 MyBatis进行数据库查询时,经常会查询到大量的结果。在代码21-3所示的例子中,我们查询到了大量的 User对象,并使用 List接受这些对象
# 17、executor包
如果从 MyBatis的所有包中选择一个最为重要的包,那就是 executor包。 executor 包,顾名思义为执行器包,它作为 MyBatis 的核心将其他各个包凝聚在了一起。 在该包的工作中,会调用配置解析包解析出的配置信息,会依赖基础包中提供的基础功能。最终,executor包将所有的操作串接在了一起,通过 session包向外暴露出一套完整的服务。
# 17.1、主键自增
许多数据库都支持主键自增功能,如 MySQL数据库、SQL Server数据库等。当然也有一些数据库不支持主键自增功能,如 Oracle数据库。MyBatis的 executor包中的 keygen子包兼容以上这两种情况
配置与生效:
- 要启动Jdbc3KeyGenerator,可以配置文件中增加setting属性或者直接在相关语句中启用
- 要启用 SelectKeyGenerator,则需要在 SQL语句前加一段 selectKey标签
如果两个都配置了,则以后者(SelectKeyGenerator)为主
# 17.2、Jdbc3KeyGenerator类
Jdbc3KeyGenerator类是为具有主键自增功能的数据库准备的 既然数据库已经支持主键自增了,那 Jdbc3KeyGenerator类存在的意义是什么呢? 它存在的意义是提供自增主键的回写功能
# 17.3、SelectKeyGenerator类
可以真正地生成自增的主键 SelectKeyGenerator类实现了 processBefore和 processAfter这两个方法
# 17.4、懒加载
aggressiveLazyLoading 是激进懒加载设置,我们对该属性进行一些说明。当aggressiveLazyLoading设置为 true时,对对象任一属性的读或写操作都会触发该对象所有懒加载属性的加载;当 aggressiveLazyLoading设置为 false时,对对象某一懒加载属性的读操作会触发该属性的加载。无论 aggressiveLazyLoading的设置如何,调用对象的“equals”“clone”“hashCode”“toString”中任意一个方法都会触发该对象所有懒加载属性的加载
功能实现:
# 17.5、语句处理功能
在 MyBatis映射文件的编写中,我们常会见到“${}”和“#{}”这两种定义变量的符号,其含义如下
- ${}:使用这种符号的变量将会以字符串的形式直接插到 SQL片段中。
- #{}:使用这种符号的变量将会以预编译的形式赋值到 SQL片段中。
MyBatis中支持三种语句类型,不同语句类型支持的变量符号不同。MyBatis中的三种语句类型如下
- STATEMENT:这种语句类型中,只会对 SQL片段进行简单的字符串拼接。因此,只支持使用“${}”定义变量
- PREPARED:这种语句类型中,会先对 SQL片段进行字符串拼接,然后对 SQL片段进行赋值。因此,支持使用“${}”“#{}”这两种形式定义变量
- CALLABLE:这种语句类型用来实现执行过程的调用,会先对 SQL 片段进行字符串拼接,然后对 SQL片段进行赋值。因此,支持使用“${}”“#{}”这两种形式定义变量
在创建 SQL语句时,语句的类型由 statementType 属性进行指定。如果不指定则默认采用 PREPARED
在对CALLABLE语句进行调用时,可以直接使用Map来设置输入参数。使用MyBatis调用存储过程的操作如下图所示:
# 18、session包
# 18.1、DefaultSqlSession类
session包是整个 MyBatis应用的对外接口包,而 executor包是最为核心的执行器包。
DefaultSqlSession 类做的主要工作则非常简单——把接口包的工作交给执行器包处理
# 18.2、SqlSessionManager类