 ES-概述
ES-概述
# ES-概述
# 1、基本概念
# 1、索引
在使用传统的关系型数据库时,如果对数据库有存取和更新操作,需要建立一个数据库。相应的,在es中则需要建立索引,用户的搜索、新增、更新等操作全部对应索引
# 2、文档
在使用传统的关系型数据库时,需要把数据封装成数据库的一条数据,而在es中对应的则是文档,每个字段可以是各种类型,用户对数据操作的最小粒度对象就是文档。es文档的操作使用了版本的概念,即文档的初始版本为1,每次写操作会把文档的版本+1,每次使用文档时,es返回用户的是最新版本的文档,另外,为了减轻集群负载和提升效率,es提供了文档的批量索引、更新、删除的功能
# 3、字段
一个文档包含一个或者多个字段,每个字段都有一个类型与之对应,除了常用的数据类型(如字符串、文本、数值等),es还提供了多重数据类型,如数组类型、经纬度类型和IP地址类型,es对不同的类型字段可以支持不同的搜索功能。例如使用文本类型的数据时,可以按照某种分词方式对数据进行搜索,并且可以设定搜索后的打分因子来影响最终的排序,再如:使用经纬度的数据时,es可以搜索某个地点附近的文档,也可以查询地理围栏内的文档,在排序函数的使用上,es也可以基于某个地点按照衰减函数进行排序
# 4、映射
建立索引时,需要定义文档的数据结构,这种结构就叫做映射,在映射中,文档的字段类型一旦设定后就不能更改。因为字段类型在定义后,es已经针对定义好的类型建立了特定的索引结构,这种结构不能更改,借助映射可以给文档增加字段。另外,es还提供了自动映射功能,即在添加数据时,如果该字段没有定义类型,es会根据用户提供的该字段的真实数据来猜测可能的类型,从而自动进行字段类型的定义
# 5、集群和节点
在分布式系统中,为了完成海量数据的存储,计算并提升系统的高可用性,需要多台计算机集成在一起协作,这种形式称之为集群
集群中的每个机器称为节点,es集群的个数不受限制,用户可以根据需求增加计算机对搜索服务进行扩展
# 6、分片
在分布式系统中,为了能存储和计算海量的数据,会对数据进行切分,然后再将他们存储到多台计算机中,这样不仅能分担集群中的存储和计算压力,而且在该架构基础上进一步优化,还可以提升系统中数据的高可用性,在es中,一个分片对应的就是一个lucene索引,每个分配分片可以设置多个副分片,这样当主分片所在的计算机因为发生故障而离线时,副分片会充当主分片继续服务。索引的分片个数只能设置一次,之后不能再更改,再默认情况下,es每个索引设置为5个分片
# 7、副分片
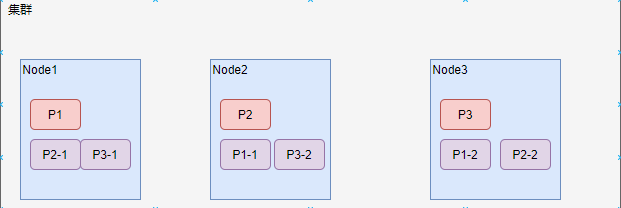
为了提升系统索引数据的高可用性并减轻集群搜索的负载,可以启用分片的副本,该副本称之为副分片,而原有的分片叫做主分片。再一个索引中,主分片的副分片的个数是没有限制的,用户可以按需设定,再默认情况之下es不会开启副分片,用户可以手动设置。副分片的个数设定后,也可以进行更改,一个分片的主分片和副分片分别存储再不同的计算机上,如下图所示,集群中有三个节点,新增一个索引,设置3个主分片P1-3,每个分片设置2个副本,这种设置再服务器节点的保存路径如下图
# 8、DSL
es使用dsl来定义查询
# 2、es和传统数据库的区别
# 1、索引
关系型数据库的索引大多数是B-Tree结构,而Es使用的是倒排索引,两种不同的数据索引方式决定了两种产品再某些场景下的性能和速度的差异。例如:对一个包含几亿条数据的关系型数据库表执行最简单的count操作,关系型数据库可能需要秒级的响应时间,如果数据表的设计不合理甚至可能把整个关系型数据库拖垮,影响其他的数据服务;而es可以在毫秒级别进行返回,该查询对于整个集群的影响特别小
# 2、事务支持
事务是关系型数据库的核心组成模块。而es是不支持事务的。es更新文档是,先读取文档再进行修改,然后再为文档重新建立索引。如果同一个文档同时有多个并发请求,则极有可能会丢失某个更新操作,为了解决这个问题,es使用了乐观锁,即假定冲突是不会发生的,不阻塞当前数据的更新操作,每次更新会增加当前文档的版本号,最新的数据由文档的版本号决定,这种机制决定了es没有事务管理
# 3、SQL和DSL
SQL是关系型数据库使用的语言,主要是因为SQL查询的逻辑比较简单和直接,一般是大小、相等之类的比较运算
es不仅包含上述运算,而且支持文本搜索、地理位置等复杂搜索,因此es'使用DSL查询进行请求通讯
# 4、扩展方式
随着数据量的迅速膨胀,关系型数据库的扩展需要借助第三方组建完成分库分表的支持,分库分表即按照某个ID取模将数打散后分散到不同的数据节点中,借此来分摊集群的压力
ES本身就是支持分片的,只要初期对分片的个数进行了合理的设置,后期是不需要对扩展进行过分担心,即使现有集群负载较高,也可以通过后期增加节点以及副分片的方式来解决
# 3、ES的架构原理
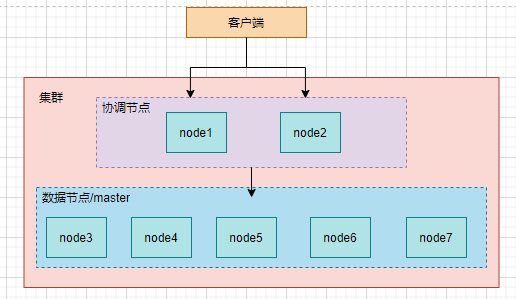
# 1、节点职责
节点按照职责可以分为master节点、数据节点、和协调节点,每个节点类型可以单独配置。默认情况下,集群不会对节点角色进行划分,所有节点都是平等的,可以担任所有的职责,但是在生产环境中需要对这些节点的角色进行最优划分,否则在高并发请求的情况下,集群容易出现服务阻塞超时甚至服务崩溃的隐患
master节点负责维护整个集群的相关工作、管理集群的变更、如创建/删除索引、节点健康状态监测、节点的上下线等。master节点时集群通过选举算法选举出来的,一个集群中只有一个节点可以生成master但是可以有多个节点参与master节点的选举。在默认情况下,任意节点都可以作为master的候选节点,可以通过配置项 node.master对当前节点是否作为master的候选节点进行控制
数据节点主要负责索引数据的保存工作,此外也执行数据的其他操作,如文档的删除、修改、查询操作。数据节点的很多工作都是调用lunece库进行Lunece索引操作,因此这种节点对于内存和IO的消耗较大,生产环境中应多注意数据节点的计算机负载情况
客户端可以向es集群的节点发起请求,这个节点叫做协调节点。在默认的情况下,协调节点可以是集群中的任意节点,此时它的生命周期和一个单独的请求相关的。也就是说,当客户端向集群中的某个节点发送请求时,测试该节点被称之为请求的协助节点,当它将响应结果返回给客户端后,该协调节点的生命周期就结束了。协调节点根据具体情况将请求转发给其他节点,并将最终的汇总结果返回给客户端
为了降低集群的负载,可以设置某些节点作为单独的协调节点,在节点的配置文件中设置node.master和node.data配置项设置为false,此时这个节点就不会被选中为master节点并且不会担任数据节点,而客户端就可以把这类节点当作协调节点来使用,把所有请求都发到这些节点上。

# 2、主分片和副分片
ES为了支持分布式的搜索,会把数据按照分片进行切分。
一个索引由一个或者多个分片构成,并且每个分片有0个或者多个副本。多个分片分布在不用的节点中,通过这种分布式的结构提升了分片数据的高可用性和服务的高并发支持
Q:如何提升分片数据的高可用性?
A:集群中的索引主分片和副分片在不同的节点上,如果某个主分片所在的节点宕机,则原有的某个副分片会提升为主分片继续对外进行服务
Q:ES如何提升服务的高并发性能?
A:
当客户端对某个索引的请求被分发到es的协调节点时,协调节点会将请求进行转发,转发的对象包含这个索引的所有分片的部分节点。协调节点中有一份 分片-->节点路由表,该节点主要存放分片和节点的对应关系,协调节点采用轮询算法,选取该索引的主/副分片所在节点进行请求转发,一个索引的主分片确定后就不能修改,如果想继续提升索引的并发性能,则可以增加索引的副分片个数,此时协调节点会将这些副分片加入轮询算法中
# 3、路由计算
Q:当客户端向es协调节点发送一个数据的写请求时,协调节点如何确认当前数据应该存储再哪个节点的哪个分片上呢?
A:协调节点根据数据获取分片ID的计算公式如下:
shard=hash(routing)%number_of_primary_shards
routing代表每条文档提交时的参数,该值是可变的,用户可以自己定义在默认情况下使用的是文档的_id
number_of_primary_shards:表示索引中主分片的个数
计算routing的hash值,对索引的主分片数取余,就是当前文档实际该存储的分片ID
获取到分片ID后,根据分片-->节点路由表获取该分片的主/副分片节点列表,然后再转发请求进行分片诶的数据写入
通过上面的公式可以观察到,主分片的个数作为取余的分母不能进行更改,否则分片ID计算就会发生错误,进而导致找不到存储节点,这也是一个索引的主分片个数不能更改的原因
# 4、文档读写过程
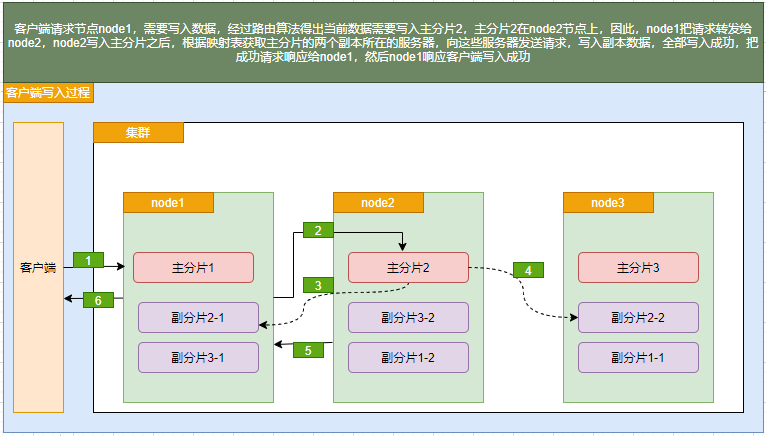
写入:当es协调节点接受到来自客户端对某个索引的写入文档请求时,该节点会根据一定的路由算法将文档映射到某个主分片上,然后将请求转发到该分片所在的节点,完成数据的存储后,该节点会将请求转发给该分片的其他副分片的所有节点,直到所有副分片节点全部完成写入,es协调节点向客户端报告写入成功
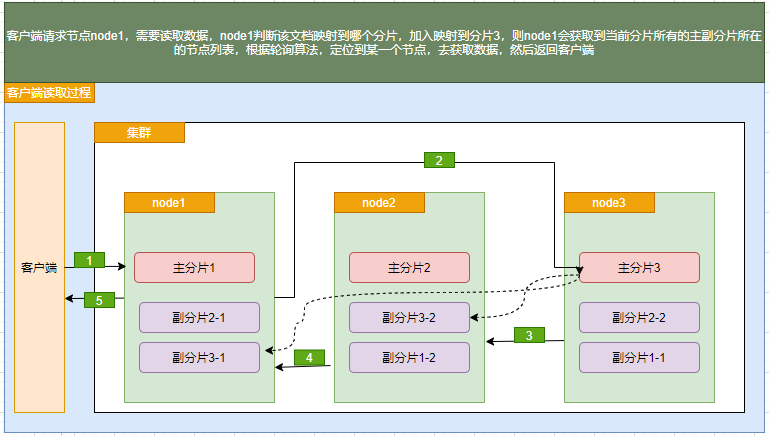
读取:当es协调节点接收到来自客户端的获取某个索引的某文档的请求时,协调节点会找到该文档所在的所有分片,然后根据轮询算法在主/副分片中选择一个分片并将请求转发给该分片所在的节点,该分片会将目标数据发送给协调节点,协调节点在将数据返回给客户端
# 4、ES安装
# 1、linux 版本安装
下载地址:https://www.elastic.co/cn/downloads/elasticsearch es的安装文件时压缩文件,把文件解压缩后,各目录的作用如下所示
目录 作用 bin 存放es启动、关闭等脚本文件 conf es配置文件所在的目录 jdk es自带的jdk目录 lib es运行时需要的jar包目录 logs 存放es的运行日志 modules 存放es已安装的模块 plugins 存放es已经安装的插件 es不允许root用户启动,需要创建其它用户进行启动es。默认情况下es进程占用的内存是1GB
useradd esuser passwd esuser tar -zxvf elasticsearch-7.3.2-linux-x86_64.tar.gz mv elasticsearch-7.3.2 elasticsearch #更改一些配置项 cd config vi jvm.options #修改默认配置:-Xms1g -Xmx1g为 512 #编辑elasticsearch.yml修改数据和日志目录 vi elasticsearch.yml cluster.name:my-es node.name:es-node0 path.data: /usr/local/es/data path.log: /usr/local/es/logs network.host: 0.0.0.0 cluster.initial_master_nodes:["es-node0"] #修改/etc/security/limits.conf文件 增加配置 vi /etc/security/limits.conf #在文件最后,增加如下配置:配置完成需要重启机器 * soft nofile 65536 * hard nofile 65536 [用户] - nproc 65535 # 例如 esuser - nproc 65535 #在/etc/sysctl.conf文件最后添加一行 vm.max_map_count=655360 添加完毕之后,执行命令: sysctl -p vi /etc/sysctl.conf vm.max_map_count=655360 sysctl -p ####开始启动es###### #1、先将es文件夹下的所有目录的所有权限迭代给esuser用户 chown -R esuser:esuser /usr/local/elasticsearch-7.5.1 su esuser #2、先切换到esuser用户启动 su esuser ./bin/elasticsearch1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 测试是否启动成功
curl -XGET 127.0.0.1:9200
#外部访问测试环境可以直接关闭防火墙 systemctl stop firewalld.service
`elasticsearch.yml的其它可配置信息:`
| 属性名 | 说明 |
| ---------------------------------- | ------------------------------------------------------------ |
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
## 2、集群启动es
> 假设使用三台机器部署集群模式,ip分别为192.168.0.1,192.168.0.2,192.168.0.3,名称分别为es1、es2、es3,需要在这3台计算机上创建除root外的用户进行集群的搭建
+ es1机器上修改配置文件 config/elasticsearch.yml
```shell
#服务器启动时绑定的IP地址
network.host: 192.168.0.1
#自动发现设置,可以通过这些节点自动发现集群中的节点
discovery.send_hosts:["192.168.0.1","192.168.0.2","192.168.0.3"]
#集群中可以参与选举master的节点列表
cluster.initial_master_nodes:["192.168.0.1","192.168.0.2","192.168.0.3"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
es2机器上的修改配置文件config/elasticsearch.yml
#服务器启动时绑定的IP地址 network.host: 192.168.0.2 #自动发现设置,可以通过这些节点自动发现集群中的节点 discovery.send_hosts:["192.168.0.1","192.168.0.2","192.168.0.3"] #集群中可以参与选举master的节点列表 cluster.initial_master_nodes:["192.168.0.1","192.168.0.2","192.168.0.3"]1
2
3
4
5
6es3机器上的修改配置文件config/elasticsearch.yml
#服务器启动时绑定的IP地址 network.host: 192.168.0.3 #自动发现设置,可以通过这些节点自动发现集群中的节点 discovery.send_hosts:["192.168.0.1","192.168.0.2","192.168.0.3"] #集群中可以参与选举master的节点列表 cluster.initial_master_nodes:["192.168.0.1","192.168.0.2","192.168.0.3"]1
2
3
4
5
6
节点配置完成后,可以按照任意顺序在三台计算机上运行 bin/elasticsearch命令,观察各计算机上logs/elasticsearch.log文件的内容,查看es启动有无报错信息
# 5、ES基本功能
前提:使用SpringBoot+RestHighLevelClient进行es客户端的集成1、pom引入
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>1
2
3
42、application.properties文件配置es信息
# es服务地址,多个服务地址使用逗号分隔 ,这一种配置需要配合配置类手动配置 elasticsearch.hosts=127.0.0.1:9200 #这种配置可以不使用配置类,属于spring自动集成 spring.elasticsearch.rest.uris=127.0.0.1:92001
2
3
4
53、建立配置类,读取配置,创建es客户端实例 ElasticsearchConfig.java
@ConfigurationProperties(prefix = "elasticsearch") @Configuration @Data public class ElasticsearchConfig extends AbstractElasticsearchConfiguration { private String hosts; @Override public RestHighLevelClient elasticsearchClient() { HttpHost[] httpHosts = Arrays.stream(hosts.split(",")).map(host -> { String[] hostParts = host.split(":"); String hostName = hostParts[0]; int port = Integer.parseInt(hostParts[1]); return new HttpHost(hostName, port, HttpHost.DEFAULT_SCHEME_NAME); }).filter(Objects::nonNull).toArray(HttpHost[]::new); RestClientBuilder builder = RestClient.builder(httpHosts); RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder); return restHighLevelClient; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
214、具体使用客户端,使用ElasticsearchRestTemplate
@Autowired private ElasticsearchRestTemplate elasticsearchRestTemplate;1
2
# 1、索引
# 1、创建索引
完成搜索的第一步是建立搜索数据集的对象,即建立索引。
在定义酒店的搜索需求时,应该包含的字段有酒店标题、所属城市和房价等,对于酒店标题来说需要按照用户输入的关键词进行模糊搜索,因此应该定义成文本(text),对于所属城市来说,只需要进行相等与否的判断可以定义为普通的关键词类型(keyword),对于房价来说,只需要进行大小比较的判断,因此定义为数值中的双精度浮点型
PUT /hotel
{
"mappings":{
"_doc" : {
"dynamic" : "false",
"properties" : {
"title":{
"type":"text"
},
"city":{
"type":"keyword"
},
"price":{
"type":"double"
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
SpringBoot集成代码,使用实体类自动创建索引
@Document(indexName = "hotel", shards = 3, replicas = 1)
public class Hotel {
@Id
private Long id;// 商品唯一标识
@Field(type = FieldType.Text)
private String title;// 商品名称
@Field(type = FieldType.Keyword)
private String city;// 分类名称
@Field(type = FieldType.Double)
private Double price;// 商品价格
}
2
3
4
5
6
7
8
9
10
11
12
13
14
1、es创建索引的请求类型是PUT,请求形式如下:
PUT /${index_name}
{
"settings":{
...
},
"mappings":{
...
}
}
2
3
4
5
6
7
8
9
变量 ${index_name} 就是创建的目标索引的名称
settings 内部填写索引相关的设置项,如主分片个数、副分片个数等
mappings 内部填写数据组织结构,即数据映射
假设 设置主分片个数为15,副分片个数是2,则对应的DSL如下:
PUT /${index_name}
{
"settings":{
"number_of_shards":15,
"num_of_replicas":2
},
"mappings":{
"properties":{
...
}
}
}
2
3
4
5
6
7
8
9
10
11
12
# 2、删除索引
1、删除索引的请求类型是DELETE
DELETE /${index_name}
//系统返回数据
{
"acknowledged": true
}
2
3
4
5
6
# 3、关闭索引
在某些场景下,某个索引暂时不使用,但是后期可能又会使用,这个使用指的是数据的写入和搜索。这个索引在某一段时间内属于冷数据或者归档数据,这时可以使用索引的关闭功能。索引关闭时,只能通过ES的API或者监控工具看到索引别的元数据信息,但是此时改索引不能写入和搜索,只有等待索引打开后,才能写入和搜索数据
请求形式 POST
POST /hotel/_close
//返回数据
{
"acknowledged": true,
"shards_acknowledged": true,
"indices": {
"hotel": {
"closed": true
}
}
}
2
3
4
5
6
7
8
9
10
11
# 4、打开索引
POST /hotel/_open
//返回数据
{
"acknowledged": true,
"shards_acknowledged": true
}
2
3
4
5
6
# 5、索引别名
别名指的是给一个或者多个索引定义另外一个名称,使索引别名和索引之间可以建立某种逻辑关系
可以用别名表示别名和索引之间的包含关系
例如:建立了1月、2月、3月的用户入住酒店的日志索引,假设当前日期是4月1号,需要搜索过去三个月的日志索引,如果分别去3个索引中搜索,这种编码方式比较低效,此时可以创建一个别名last_three_month,然后设置前面三个索引的别名为last_three_month,这样就可以在last_three_month这个索引里面进行搜索
如下可以代码演示:
//新建索引/january_log february_log march_log
PUT /january_log
{
"mappings":{
"_doc" : {
"dynamic" : "false",
"properties" : {
"uid":{
"type":"keyword"
},
"hotel_id":{
"type":"keyword"
},
"check_in_date":{
"type":"keyword"
}
}
}
}
}
//另外两个索引一样
...
...
//写入数据
POST /january_log/_doc/001
{
"uid": "001",
"hotel_id":"92999",
"check_in_date":"2022-01-01"
}
POST /february_log/_doc/001
{
"uid": "001",
"hotel_id":"92999",
"check_in_date":"2022-02-02"
}
POST /march_log/_doc/001
{
"uid": "001",
"hotel_id":"92999",
"check_in_date":"2022-03-03"
}
//建立别名last_three_month,设置上面三个索引的别名都是last_three_month
POST /_aliases
{
"actions": [
{
"add": {
"index": "january_log",
"alias": "last_three_month"
}
},
{
"add": {
"index": "february_log",
"alias": "last_three_month"
}
},
{
"add": {
"index": "march_log",
"alias": "last_three_month"
}
}
]
}
//在last_three_month索引下搜索uid为001的用户入住记录
GET /last_three_month/_search
{
"query":{
"term":{
"uid":001
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
注意:如果一个别名指向多个索引,则向这个别名写入数据会报错因为es在默认情况下不确定向别名写入数据时的转发对象是哪个,这种情况需要在设置别名时进行设置,将目标索引的is_write_index属性设置为true来执行该索引可用于执行数据的写入操作。
例如:january_log作为数据写入的转发对象
POST /_aliases
{
"actions": [
{
"add": {
"index": "january_log",
"alias": "last_three_month",
"is_write_index":true
}
}
]
}
2
3
4
5
6
7
8
9
10
11
12
引入了别名之后,还可以用别名标识索引之间的替代关系。这种关系一般是在某个索引被创建后,有些参数不能更改(如主分片的个数),但是随着业务发展,索引中的数据增多,需要更改索引参数进行优化。需要平滑的解决问题,既要更改索引的设置,又不能改变索引名称,这时就可以使用索引别名
# 6、映射操作
在使用数据之前,需要构建数据的组织结构,这种组织结构在关系型数据库叫做表结构,在ES中称之为映射。
ES可以在数据写入时猜测数据类型,从而自动创建映射,但有时会出现不准确的情况,当需要严格控制数据类型时,还是需要用户手动创建映射
映射查看
GET /${index_name}/_mapping1扩展映射
映射中的字段类型是不可以修改的,但是字段可以扩展,最常见的扩展方式就是增加字段和为object(对象)类型的数据新增属性,例如:下面的操作是扩展hotel索引,并增加tag字段POST /hotel/_mapping { "properties": { "tag":{ "type":"keyword" } } }1
2
3
4
5
6
7
8
# 7、基本数据类型
keyword keyword类型是不进行切分的字符串类型。指的是在索引时,对keyword类型的数据不进行切分,直接构建倒排索引;在搜索时,对该类型的查询字符串不进行切分后的部分匹配。keyword类型数据一般用于对于文档的过滤、排序和聚合,在查询时一般使用term进行精准匹配
text text类型是可以进行切分的字符串类型,指的是在索引时,可以按照相应的切词算法对文本内容进行切分,然后构建倒排索引;在搜索时,对该类型的查询字符串按照用户的切词算法进行切分,然后对切分后的部分匹配打分,在查询时一般使用match进行模糊匹配
数值类型 es支持的数值类型有long、integer、short、byte、double、float、half_float、scaled_float和 unsigned_long等 对于数值类型,一般使用term搜索或者range范围搜索
布尔类型 布尔类型使用boolean定义,用于业务中的二值表示,表示是否,值可以是true或者字符串的"true"
日期类型 es中日期类型的名称为date。es中存储的日期是标准的UTC格式,比如定义一个create_time字段,类型为date,
POST /hotel/_mapping { "properties": { "create_time":{ "type":"date" } } } //写入数据 POST /hotel/_doc/001 { "title":"好再来", "create_time":"20221116" } //注意:日期类型默认不支持 yyyy-MM-dd HH:mm:ss格式,如果业务中经常使用这种格式,可以在索引的mapping中设置日期格式的format属性为自定义格式 POST /hotel/_mapping { "properties": { "create_time":{ "type":"date", "format":"yyyy-MM-dd HH:mm:ss" } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25一般情况下使用如下形式表示日期类型数据 1、格式化的日期字符串 2、毫秒级的长整型(1970到现在的毫秒数) 3、秒级别的整数(1970到现在的秒数)
格式化的日期字符串一般支持如下yyyy-MM-dd、yyyyMMdd、yyyyMMddHH-mm-ss、yyyy-MM-ddTHH:mm:ss
yyyy-MM-ddTHH:mm:ss.SSS 、yyyy-MM-ddTHH:mm:ss.SSSZ等格式
# 8、复杂的数据类型
数组类型 1、es数组没有定义方式,使用方式也是开箱即用的,无须事先声明,在写入时把数据使用中括号[]括起来,由es对该字段完成定义 如果事先已经定义了字段类型,在写入数据时已数组的形式写入,es也会把该类型转为数组
POST /hotel/_doc/001 { "tag":["有车位","免费wifi"] }1
2
3
42、查询数组类型:数组类型的字段适用于元素类型的搜索方式,也就是说,数组元素适用于什么类型的搜索,数组字段就适用于什么搜索,那么在上面的示例中,数组元素类型是keyword,则使用term搜索
GET /hotel/_search { "query": { "term": { "tag": "有车位" } } }1
2
3
4
5
6
7
8对象类型 1、在实际业务中,一个文档需要包含其他内部对象。例如在酒店搜索需求中,用户希望酒店信息中包含评论数据。评论数据包含差评和好评,为了支持这种业务,在es中可以使用对象类型,和数组类型一样,对象类型也不需要提前定义,在写入文档的时候,es会自动识别并转换为对象类型
PUT /hotel/_doc/005 { "title": "希尔酒店", "city": "郑州", "price": 888.88, "comment_info": { "properties": { //好评 "favourable_comment":199, //差评 "negative_comment":20 } } }1
2
3
4
5
6
7
8
9
10
11
12
13
142、对象类型的属性进行搜索,可以直接使用点" . "操作符进行指向,例如搜索hotel索引中好评数大于100的文档
GET /hotel/_search { "query":{ "range":{ "comment_info.properties.favourable_comment":{ "gte": 100 } } } }1
2
3
4
5
6
7
8
9
10地理类型 1、该类型的定义需要在mapping中指定目标字段的数据类型为
geo_point类型POST /hotel/_mappings { "properties": { "localtion":{ "type":"geo_point" } } }1
2
3
4
5
6
7
82、向localtion字段中写入数据
POST /hotel/_doc/001 { "title": "好再来", "create_time": "20221116", "localtion":{ "lat":40.012134, "lon":116.497553 } }1
2
3
4
5
6
7
8
9
# 9、动态映射
当字段没有定义时,es根据写入的数据自动定义盖子点的类型,这种机制称之为动态映射 在一般情况下,如果使用基本类型数据,最好先把数据类型定义好,因为es的动态映射生成的字段类型可能会与用户的预期有差别。
# 10、多字段
使用场景:针对同一个字段,有时候需要不同的数据类型,这通常表现在为了不同的目的以不同的方式索引相同的手段。在订单系统中,既希望能够按照用户姓名进行搜索,又希望按照姓氏进行排序,那就可以在mapping定义中将姓氏字段先后定义为keyword类型和text类型,其中keyword类型的字段称之为
子字段,这样es在创建索引时会将姓名字段建立两份索引
PUT /hotel_order
{
"mappings":{
"_doc" : {
"dynamic" : "false",
"properties" : {
"order_id":{
"type":"keyword"
},
"user_id":{
"type":"keyword"
},
//user_name索引text,然后创建子字段为keyword类型,使用fields关键字
"user_name":{
"type":"text",
"fields":{
"user_name_keyword":{
"type":"keyword"
}
}
},
"hotel_id":{
"type":"keyword"
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
1、写入数据演示查询
GET /hotel_order/_search
{
"query": {
"match": {
"user_name": "张"
}
},
"sort": [
{
"user_name.user_name_keyword": "desc"
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
# 2、文档
# 1、单条写入文档
创建好索引之后,往里面填充一条数据
//固定格式
POST /${index_name}/_doc/${_id}
//id如果不传值,则es会自动生成
POST /hotel/_doc/001
{
"title": "好再来酒店",
"city":"青岛",
"price":"666.88"
}
2
3
4
5
6
7
8
9
10
1、SpringBoot集成的方式填充一条数据
@Test
public void insertSingleDoc() {
Hotel h = new Hotel();
h.setCity("北京");
h.setTitle("希尔酒店");
// 第一种
hotelRepository.save(h);
// 第二种
elasticsearchRestTemplate.save(h);
}
2
3
4
5
6
7
8
9
10
# 2、批量写入文档
使用POST _bulk可以批量插入文档数据,但是数据两太多的情况下还是使用linux中的curl进行数据的批量写入
curl命令支持上传文件,用户可以将批量写入的json数据保存到文件中,然后使用curl命令提交
在es单机环境下登录服务器,然后执行curl命令将双数两个文档批量写入hotel索引中
curl -s -XPOST '127.0.0.1:9200/_bulk?pretty' --data-binary "@bulk_doc.json"
#其中bulk_doc.json是文件名称
2
3
1、SpringBoot集成执行批量插入doc
@Test
public void insertBulkDoc() {
List<Hotel> hs = new ArrayList<>();
Hotel h = new Hotel();
h.setCity("北京");
h.setTitle("希尔酒店");
Hotel h1 = new Hotel();
h1.setCity("北京1");
h1.setTitle("希尔酒店1");
hs.add(h);
hs.add(h1);
// 第一种
hotelRepository.saveAll(hs);
// 第二种
elasticsearchRestTemplate.save(hs);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 3、更新单条文档
1、请求的固定格式为
POST /${index_name}/_update/${_id}
{
“doc”:{
...
}
}
//例如:
POST /hotel/_update/001
{
"doc":{
"city":"广州"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
其中id就是需要更新的具体哪个文档的id
2、SpringBoot集成更新单条文档
@Test
public void updateSingleDoc() {
Optional<Hotel> byId = hotelRepository.findById("001");
if (byId.isPresent()) {
Hotel hotel = byId.get();
hotel.setCity("update--city");
hotelRepository.save(hotel);
}
}
2
3
4
5
6
7
8
9
# 4、批量更新文档
1、批量更新文档的请求形式如下:
POST /_bulk
2
2、SpringBoot集成更新批量文档
@Test
public void updateBulkDoc() {
Iterable<Hotel> all = hotelRepository.findAll();
for (Hotel hotel : all) {
hotel.setCity("update--city");
}
hotelRepository.saveAll(all);
}
2
3
4
5
6
7
8
# 5、根据条件更新文档
在索引数据的更新操作中,有些场景需要根据某些条件同时更新多条数据,类似update table table_name set ... where ...更新一批数据,为了满足这样的需求,
es为用户提供了_update_by_query功能
POST /${index_name}/_update_by_query
{
"query":{
//更新的查询条件
...
},
"script":{
//具体更新的脚本代码
...
}
}
//示例:
POST /hotel/_update_by_query
{
"query": {
"term": {
"price": "888.88"
}
},
"script": {
"source": "ctx._source['price'] = '999.99'"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
如果在_update_by_query中不定义query,则代表更新所有数据
# 6、删除单条文档
1、删除请求形式如下:
DELETE /${index_name}/_doc/${_id}
如果删除一个不存在的文档,则会报错
# 7、批量删除文档
1、请求形式如下
POST /_bulk
{"delete":{"_index":"${index_name}","_id":"${_id}"}}
{"delete":{"_index":"${index_name}","_id":"${_id}"}}
2
3
# 8、根据条件删除文档
1、关键字为_delete_by_query,请求格式如下
POST /${index_name}/_delete_by_query
{
"query":{
...
}
}
2
3
4
5
6
# 3、搜索
# 1、指定返回的字段
生产情况下,考虑到性能问题,需要对搜索结果进行“瘦身”,在es中,通过_source子句可以设定返回结果的字段。_source指向json数组。数组中的元素是希望返回的字段名称
# 1、根据ID查询文档
一个简单的搜索,根据文档的id直接定位某个文档,例如查询id为001的文档数据
GET /hotel/_doc/001
//返回结果
{
"_index": "hotel",
"_type": "_doc",
"_id": "001",
"_version": 1,
"_seq_no": 0,
"_primary_term": 3,
"found": true,
"_source": {
"title": "好再来酒店",
"city": "青岛",
"price": "666.88"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
返回结果中包含了文档的元数据,比如是否找到、索引名称、文档ID、文档版本,只有在_source中展示了命中的文档的原始数据。
# 2、根据一般字段搜索文档
需要使用query子查询,请求形式如下,query子句可以按照需求填充查询项,假设按照价格进行搜索,因为只需要判断是否相等,所以需要用到term搜索,类似于sql中的 =
GET /${index_name}/_search
{
"query": {
"term": {
"price": {
"value": 666.99
}
}
}
}
//返回结果
{
"took": 29,
"timed_out": false,
//命中的分片信息
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
//命中的文档总数
"total": {
"value": 1,
"relation": "eq"
},
//命中文档中的最高分
"max_score": 0.2876821,
//命中文档的集合
"hits": [
{
//文档所在索引
"_index": "hotel",
"_type": "_doc",
"_id": "001",
//文档分值
"_score": 0.2876821,
"_source": {
"title": "好再来酒店",
"city": "青岛",
"price": "666.99"
}
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 3、根据文本字段搜索文档
对于文本进行模糊匹配并给出匹配分数这已功能是搜索引擎独有的,对于文本类型使用match进行模糊匹配,类似与SQL中的like
GET /hotel/_search
{
"query": {
"match": {
"title":"再来"
}
}
}
//返回结果
{
"took": 42,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.5753642,
"hits": [
{
"_index": "hotel",
"_type": "_doc",
"_id": "001",
"_score": 0.5753642,
"_source": {
"title": "好再来酒店",
"city": "青岛",
"price": "666.99"
}
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
SpringBoot集成代码示例1
@Test
public void getHotelFromTitle() {
NativeSearchQueryBuilder query =
new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("title", "再来"));
SearchHits<Hotel> search = elasticsearchRestTemplate.search(query.build(), Hotel.class);
System.out.println("查询条数:" + search.getTotalHits());
List<SearchHit<Hotel>> searchHits = search.getSearchHits();
for (SearchHit<Hotel> hotelSearchHit : searchHits) {
Hotel hotel = hotelSearchHit.getContent();
System.out.println(hotel);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
SpringBoot集成代码示例2
HotelRepository.java
@Repository
public interface HotelRepository extends ElasticsearchRepository<Hotel, Long> {
List<Hotel> findByTitleLike(String title);
}
@Test
public void getHotelFromTitleByDao() {
List<Hotel> search = hotelRepository.findByTitleLike("再来");
System.out.println("查询条数:" + search.size());
for (Hotel hotel : search) {
System.out.println(hotel);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15